 023-68661681
023-68661681
 返回
返回

无论数据是大大小小,是旧数据还是新数据,传统数据还是现代数据,无论是在内部还是在云端,对数据质量的需求都不会改变。处于从大数据和其他新数据资产中获取业务价值的压力下的数据专业人员可以利用现有技能,团队和工具来确保大数据的质量。即便如此,仅仅因为您可以利用现有技术也不意味着这就是您应该做的。我们必须使现有技术适应当前时代的要求。

数据专业人员必须调整,优化和扩展数据质量及相关数据管理最佳实践,以适应大数据和类似现代数据集的业务和技术要求,才能保护传统企业数据的质量。 除非组织两者都做,否则它可能无法提供所有数据资产所期望的那种可信分析,操作报告,自助服务功能,业务监控和治理。
调整和优化使数据质量任务与大数据相关
好消息是,组织可以将当前的数据质量和其他数据管理能力应用于大数据。但是组织仍然需要了解并进行某些调整和优化。熟悉的数据质量任务和工具功能与大数据和其他有价值的新数据资产(从Web应用程序,社交媒体,数字供应链,SaaS应用程序和物联网)高度相关,如下所示。
- 标准化。广泛的用户期望以依赖基于SQL的工具的自助服务方式探索和使用大数据。数据质量的标准化使大数据更适合临时浏览,可视化和查询。
- 删除重复数据。大数据平台总是以相同的数据加载多次而告终。这会歪曲分析结果,使度量标准计算不准确,并对运营流程造成严重破坏。数据质量的多种匹配和重复数据删除方法可以补救数据的冗余。
- 匹配。数据集之间的链接可能很难发现,特别是当数据来自传统和现代的各种源系统时。数据质量的数据匹配功能有助于验证各种数据并确定数据集之间的依存关系。
- 分析和监视。许多大数据源-例如电子商务,Web应用程序和物联网(IoT)-缺乏一致的标准,并且无法预知地发展其架构而无需通知。无论是在开发中对大数据进行概要分析还是在生产中对其进行监视,数据质量解决方案都可以在出现新方案和异常时揭示它们。数据质量的业务规则引擎和新的智能算法可以自动进行大规模补救。
- 客户数据。似乎维持有关客户的传统企业数据的质量挑战还不够,许多组织现在正在从智能手机应用程序,网站访问,第三方数据提供商,社交媒体以及不断增长的客户渠道和接触点列表中捕获客户数据。对于这些组织,客户数据是新的大数据,所有成熟的数据质量工具均具有针对客户领域设计的功能。这些工具中的大多数最近已更新,以支持大数据平台和云,以利用它们的速度和规模。
- 工具自动化。大数据是如此之大(大小,复杂性,来源和用途),以至于数据专业人士和分析人员难以准确,高效地将工作扩展到大数据。此外,一些业务用户想要大规模地以自助方式探索和分析数据,发现质量问题和机会,甚至自行修复数据。两种情况都需要工具自动化。
数据质量工具长期以来一直支持业务规则,以自动做出一些开发和补救决策。业务规则并没有消失-多种类型的用户仍然发现它们很有用,许多用户拥有庞大的规则库,他们无法放弃。
业务规则与新的自动化方法结合在一起,新的自动化方法已经出现在各种数据管理工具中,包括数据质量工具。这些通常采用智能算法的形式,这些算法基于人工智能和机器学习来应用预测功能,以自动确定数据状态,要应用的质量功能以及如何与开发人员和用户协调这些动作。
Minitab 是质量改进和统计学教育方面领先的软件和服务提供商。Minitab 通过提供一套全面的一流统计分析和过程改进工具,帮助公司和机构找出趋势、解决问题和发掘宝贵见解。
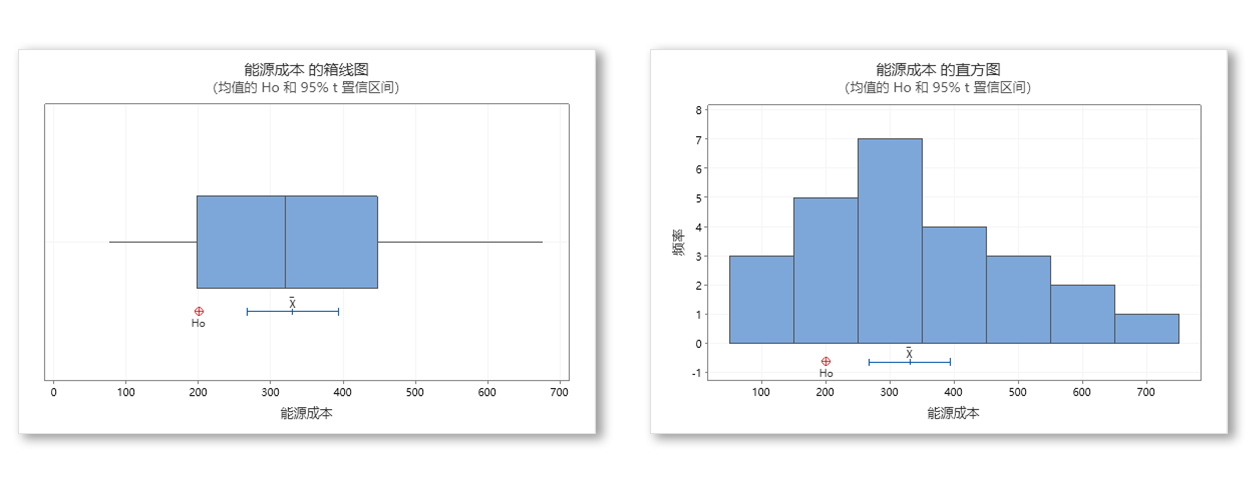
数据质量必须采用现代数据管理的新范式

必须更改数据质量的实践(以及数据集成,元数据管理和客户视图的相关实践)以遵循不同的范例。请注意,在以下示例中,大多数范式转换对于满足大数据分析中的新要求都是必需的。
- 尽早摄取大数据。数据管理中最强劲的趋势之一是更快地存储输入数据,以便对时间敏感的流程(如运营报告和实时分析)尽早访问大数据。在这些情况下,持久数据优先于提高数据质量。 为了加快数据到存储的持久性,在用户和进程可以在以后访问或重新利用大数据时进行这些改进的假设下,最小化或省略了数据的前期转换或聚合。
- 实时获取大数据质量。这些范式转移的后果是,在读取或分析时,数据聚合和质量改进正在不断地进行中。这使数据质量执行更接近实时。此外,动态大数据质量功能有时会嵌入其他解决方案中,尤其是那些用于数据集成,报告和分析的解决方案。为了实现嵌入并实现实时性能,现代工具将大多数数据质量功能作为服务提供。幸运的是,当今的快速CPU,内存处理,数据流水线和MPP数据架构提供了在大数据规模上即时执行数据质量所需的高性能。
- 保留大数据的到达(原始)状态,以备将来使用。新建立的具有大数据的最佳做法是保留从源头到达时的所有详细内容,结构,条件,甚至异常情况。存储和保护大数据的到达状态为需要详细源信息的用例提供了一个庞大的数据存储区(通常是数据湖)。 用例包括数据探索,数据发现以及基于挖掘,集群,机器学习,人工智能以及预测算法或模型的面向发现的分析。
- 并行数据质量。如今,Hadoop,数据湖和其他大数据环境的最佳实践是维护大量的详细原始数据存储,作为一种源归档。用户无需转换源,而是制作需要质量改进的数据子集的副本,并将数据质量功能应用于子集。同样,数据科学家和分析师创建了所谓的数据实验室和沙箱,以在其中改进数据以进行分析。这种“并行的数据质量”对于保留大数据的原始价值,同时通过成熟的数据质量功能创造另一种价值是必要的。
- 上下文相关的数据质量。如今,分析用户倾向于对大数据子集进行尽可能少的修改,因为大多数现代分析方法都倾向于与原始的详细源数据配合使用,并且分析通常依赖于发现的异常情况。例如,非标准数据可能是欺诈的迹象,而异常值可能是新客户群的预兆。作为另一个示例,可能需要详细的源数据来准确量化客户资料,完整视图和绩效指标。
关于慧都大数据分析平台
慧都大数据分析平台「GetInsight®」升级发布,将基于企业管理驾驶舱、产品质量分析及预测、设备分析及预测等大数据模型的构建,助力企业由传统运营模式向数字化、智能化的新模式转型升级,抓住数据经济的发展势头,提供管理效能,精准布局未来。了解更多,请联系在线客服。
慧都大数据专业团队为企业提供商业智能大数据平台搭建,免费业务咨询,定制开发等完整服务,快速、轻松、低成本将任何Hadoop集群从试用阶段转移到生产阶段。

发表评论