 023-68661681
023-68661681
 返回
返回

制造企业做质量追溯,很多时候不是缺系统,而是缺一条可信、稳定、可复用的数据链路:关键参数采得全不全、时间对不对得上、口径能不能长期稳定。一旦设备数据底座不扎实,追溯就会变成“每条线一套口径、每个工位一套脚本、每次改造都要返工”。
要把追溯做成可长期运营的能力,核心思路是把“通用问题”收敛到采集层:用一款专业的OPC Server软件与设备数据采集软件,把碎片化设备信号组织成结构化数据服务。本文以Takebishi旗下的 DeviceXPlorer OPC Server(简称DXPServer)为主线,讲清楚追溯需要哪些数据、常见架构怎么搭,以及如何通过边缘治理与标签建模提升追溯的可用性与性价比。
一、质量追溯真正要解决什么问题?
质量追溯的本质不是“记录合格/不合格”,而是让每一件产品都能回答三个问题:
- 我是谁:序列号/VIN/条码/RFID 等唯一标识及其流转路径。
- 我经历了什么:每个工位/工艺步骤发生了什么过程事件(开始、完成、报警、停线等)。
- 当时的过程条件是什么:关键工艺参数、检测结果、设备状态是否满足要求。
因此,追溯不是单点数据采集,而是一套“标识—事件—参数—状态”的证据链。
二、追溯需要哪些设备数据?按“四类证据”整理
1)产品标识与过站信息(追溯主键)
- 序列号/VIN/条码/RFID(唯一标识)。
- 工单、批次、工艺路线、工位编号、过站时间戳。
- 线体/班组/设备/工装 ID(用于责任边界定位)。
2)关键工艺参数(最核心的过程证据)
- 拧紧:扭矩、角度、OK/NOK、曲线特征、重试次数、工具ID。
- 压装:压力/位移曲线、峰值、保持时间、判定结果。
- 涂胶/点胶:胶量、速度、压力、轨迹、批次号。
- 温控/烘干:温度曲线、保温时间、上下限报警、炉号/工位号。
- 检测/测试:测量值、阈值、判定、失败码与原始记录。
3)设备状态与异常(解释“为什么”)
- 运行/待机/故障/急停、报警码、停线原因与恢复时间。
- 关键部件寿命计数、点检/保养状态。
- 过程超限事件、异常波动(对质量影响往往更大)。
4)材料与批次关联(召回与定位的关键)
- 关键物料批次、供应商、来料检验结果。
- 材料使用时间窗与工位绑定(用于精准定位影响范围)。
这四类数据要能对得上同一个产品标识,并保持长期一致口径,追溯才能真正落地。
三、追溯项目最常见的“坑”:采到了,但不好用
追溯系统上线后“不好用”,通常不是因为采不到数据,而是因为数据无法长期稳定被消费:
- 命名与层级不统一:同一参数在不同线体叫法不同,难以跨线对比与复用。
- 单位与精度不统一:扭矩/压力等关键参数需要一致口径,否则追溯记录不可比。
- 时间对齐困难:采样周期不一致、事件抖动导致与过站时间无法匹配。
- 异常值与缺失:尖峰、抖动、掉点使记录不可信,后续分析误判。
- 逻辑散落在各系统:过滤、聚合、判定写在不同脚本里,维护与交接困难。
这些问题如果不在采集层收敛治理,追溯就会不断返工,成本越滚越大。

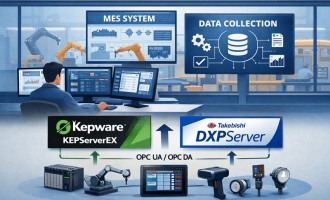
四、推荐架构:用 DXPServer 把“设备信号”变成“追溯数据服务”
更可持续的追溯架构通常是:
- 设备层:PLC、机器人、拧紧控制器、测试台、视觉、仪表等产生原始信号。
- 采集与边缘层(DXPServer):统一接入协议,建立标签模型,做必要的边缘治理。
- 业务层:MES/追溯系统接收产品标识与过站事件;质量系统/数据平台消费过程参数与异常事件。
DXPServer 在这里承担的角色,是将底层寄存器与碎片信号组织成结构化的“工位—工艺—参数”数据目录,并以 OPC UA/DA 等方式对外提供稳定数据服务(必要时也可与 MQTT/REST 等方式协同,视方案与版本而定)。
五、DXPServer 如何提升追溯的“可用性”?三项关键能力
1)标签建模:让追溯点位成为可复用资产
追溯最怕“每次对接都从头解释点位”。DXPServer 支持按产线/工位/设备/变量建立结构化标签模型,并把以下信息沉淀在标签层:
- 命名规范与层级路径(便于跨线复用与复制);
- 单位、精度、缩放系数(减少上层换算与口径分裂);
- 描述与分类(过程参数、结果、状态、计数、报警)。
2)边缘治理:让数据可信、可对齐、可长期运营
追溯数据要可用,必须“干净”。DXPServer 作为偏治理型的设备数据采集软件,适合把通用处理前移到边缘侧,例如:
- 异常过滤与防抖:避免抖动信号导致重复记录、重复报工。
- 采样与聚合:将秒级高频数据整理为工步级记录,减少无效数据与存储压力。
- 缺失与异常策略:按规则处理掉点、超限、尖峰,形成可解释的追溯记录。
- 虚拟点/派生逻辑:如 OK/NOK 判定、重试计数、状态组合、工位完成条件。
3)多系统复用:追溯数据不只给追溯系统用
追溯数据通常还会被质量分析、SPC、看板与数据平台消费。DXPServer 把数据目录与治理规则沉淀在采集层后,上层系统对接更像“订阅同一份数据服务”,而不是各自搭一套采集与清洗链路,从而显著降低重复建设。
六、性价比视角:为什么追溯底座越早“做扎实”,越省钱?
追溯场景的成本大头往往是长期的“持续治理”:
- 口径维护:命名、单位、精度、状态码长期一致;
- 扩线扩工位:新增点位能否快速按模板复制,避免返工;
- 可信数据处理:过滤、防抖、聚合、派生逻辑若散落在各系统,维护成本会不断累积;
- 多系统用数:同一份追溯数据服务质量分析与云端时,是否需要再做一套接口。
DXPServer 把“通用治理与结构化建模”收敛在采集层,能显著降低上述隐性人力成本,并减少扩线扩厂时的重复投入。对国内多品牌混线、持续迭代的工厂来说,这种长期收益往往比单纯的授权费用差异更关键,因此综合性价比更高。
质量追溯要做成可运营能力,关键是建立“可信数据链路”:采得稳、口径统一、时间对齐、异常可控,并能被长期复用。把这些通用能力沉淀在采集层,是追溯项目少返工、可扩展、可复制的核心。
如果你的追溯项目存在多品牌设备、追溯字段多且变化频繁、并希望追溯数据未来还能服务质量分析与数据平台,建议优先评估 Takebishi 旗下的 DeviceXPlorer OPC Server(简称DXPServer)作为追溯数据底座。它作为一款更偏“边缘治理型”的 OPC服务器软件 / 设备数据采集软件,往往能在交付确定性、持续迭代与长期性价比方面,带来更贴近国内工厂的实践价值。
慧都科技(EVGET)成⽴于2003年,是⼀家⾏业数字化解决⽅案公司,⻓期专注于软件、油⽓与制造⾏业。公司基于深⼊的业务理解与管理洞察,以系统化的业务建模驱动技术落地,帮助企业实现智能化运营与⻓期竞争优势。
Takebishi 作为慧都制造领域下工业物联网方向的专业厂商,能够为企业提供设备数据采集、通信协议转换、边缘计算网关等产品及应用场景解决方案。而慧都科技作为国内核心代理商,能够为您提供这款产品的正版试用下载、报价、购买、技术支持等全方位服务。
如果你想详细了解上述产品的功能、价格、授权方式、下载试用等,请拨打慧都的客服电话(023-68661681),或直接访问慧都官网(www.evget.com)咨询客服!



发表评论