 023-68661681
023-68661681
 返回
返回

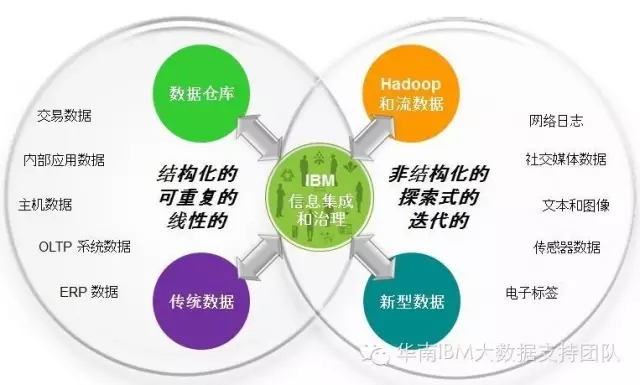
一、大数据已成为企业信息供应链中的重要一环
我们对大数据的认知在前几年还仅仅停留在概念和理论中,但转眼间,你会发现身边的大数据项目如雨后春笋般拔地而起,大数据俨然成为当今热得不能再热的话题和焦点。因为Hadoop及其相关开源技术的横空出世和迅猛发展,越来越多的企业发现那些尘封已久的历史数据或每天正在以指数级产生的交易数据、日志数据和客户行为数据其实蕴藏着巨大的价值,犹如一座座尚未开发的金矿,谁能抢占先机,就能挖掘并实现巨大的商业价值。互联网企业深谙此道,利用大数据分析结果进行产品推广和定向营销,大大改善了消费者的购物体验和消费习惯,在收获口碑的同时也赚得盆满钵满!与此同时,传统企业也在积极转型,纷纷将Hadoop大数据平台纳入到现有的IT架构和解决方案,那么如何将传统数据和大数据进行高效的集成、管理和分析呢?如何保证数据的准确性,一致性和可靠性呢?带着众多疑问,我们来看看IBM所提供的DataStage大数据集成方案,一切必将豁然开朗。
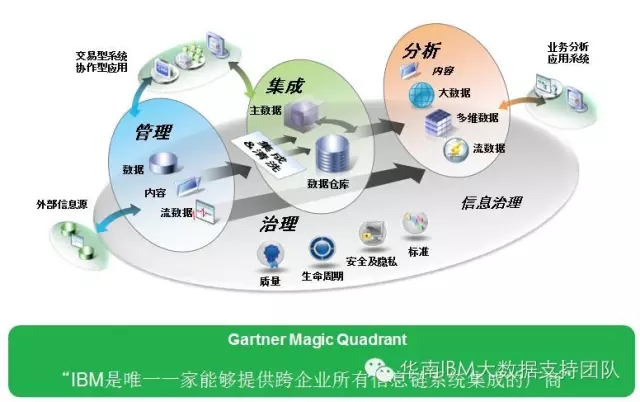
二、大数据集成所面临的挑战
1.新型的数据存储
- 大数据引入了新型的数据存储,例如,Hadoop及NoSQL,这些新型的数据存储都需要集成。
- 没有好的传统方法能够有效集成这些新型数据存储。
2.新的数据类型及格式
- 非结构化数据;半结构化数据;JSON, Avro ...
- 视频、文档、网络日志 ...
- 如何有效处理复杂且多样化的数据
3.更大的数据量
- 需要针对更大的数据量进行数据移动,转换,清洗等等。
- 需要更好的可扩展性
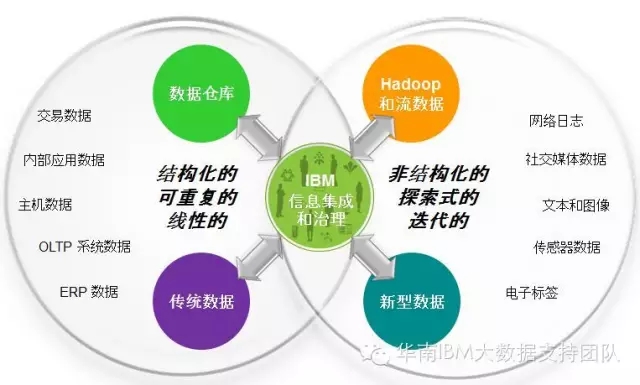
三、大数据信息整合是Hadoop项目成败的关键
大部分的Hadoop方案包括以下阶段:
- 数据收集
- 数据移动
- 数据转换
- 数据清洗
- 数据整合
- 数据探查
- 数据分析
由于面对的是基于海量的,彼此孤立的异构数据源和数据类型,所以大部分企业的Hadoop项目将花费80%的精力在数据整合上,而仅有20%的精力用于数据分析。可见,数据集成对Hadoop项目的成败有多重要。

四、IBM大数据集成解决方案:InfoSphere DataStage
1. 集中、批量式处理:整合和连接、清洗转换大数据
- Hadoop大数据作为源和目标,同现有企业信息整合;
- 与现有整合任务具备同样的开发界面和逻辑架构;
- 将处理逻辑下压至MapReduce,利用Hadoop平台最小化网络开销;
- 通过InfoSphere Streams流处理进行实时分析流程;
- 验证和清洗大数据源的数据质量;
- 贯穿大数据和/或传统数据流通过世系跟踪和血缘分析;
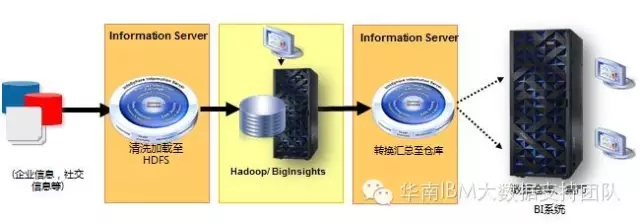
2.面向大数据和传统数据的丰富接口,支持企业所有的数据源和目标
- 对DBMS(DB2, Netezza, Oracle, Teradata, SQL Server, GreenPlum,…)提供高性能的原生API;
- 提供特定的ERP连接器;
- 基于JDBC、ODBC连接器提供灵活支持(MySQL);
- 支持简单和复杂的文件格式 (Flat, Cobol, XML, native Excel);
- 支持扩展数据源:Web Services, Cloud, Java
- 连接Hadoop文件系统(HDFS),提供可扩展的并行读写
- 直连InfoSphere Streams,支持实时分析处理
- 提供对NoSQL数据源(Hive,HBase,MongoDB,Cassandra)的支持

3.最广泛的异构平台支持
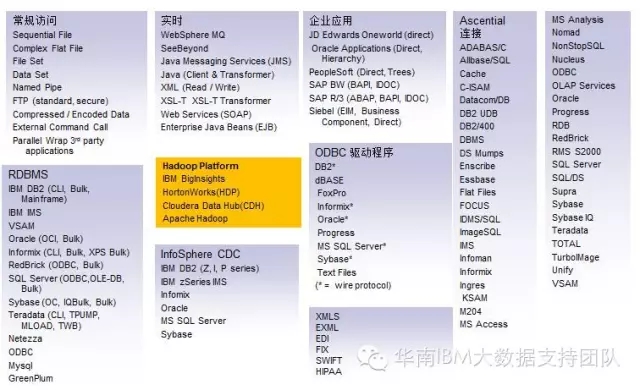
4.IBM大数据集成方案带给客户的惊喜

五、DataStage连通Hadoop的最佳实践
在DataStage中,可通过File Connector组件或Big Data File组件来连接Hadoop平台,从而将传统RDBMS数据库或本地文件中的数据加载到HDFS。比较而言,Big Data File组件支持IBM BigInsights,提供更佳的读写性能;而File Connector组件则通过WebHDFS接口或HttpFS接口访问HDFS,不依赖于Hadoop的品牌和版本,提供更广泛的兼容性。
FileConnector是DataStage v11.3面向Hadoop的全新组件,提供以下功能:
- 可用于读/写Hadoop文件系统(HDFS)
- 支持并行处理和线性扩展
- 不需要安装其他Hadoop客户端软件包
- 支持Kerberos认证
- 支持SSL安全访问协议
- 支持Knox gateway
- 支持通过WebHDFS,HttpFS方式访问Hadoop
- 支持访问本地的Hadoop节点
- 更全面的支持Hadoop(不依赖于其版本变更)
下面以Apache Hadoop v2.7为例,介绍通过配置File Connector将Oracle表数据写入HDFS的方法:
1.安装DataStage v11.3.1(参考以下链接)
http://www-01.ibm.com/support/knowledgecenter/SSZJPZ_11.3.0/com.ibm.swg.im.iis.install.nav.doc/containers/cont_iis_information_server_installation.html?lang=en
2.配置Kerberos安全认证
将Apache Hadoop服务器上的krb5.conf文件(KDC配置信息)复制到DataStage服务器上的/etc目录。
3.检查Apache Hadoop的HDFS配置文件,确认已启用WebHDFS支持

如何配置WebHDFS Rest API for Apache Hadoop v2.7:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
4.配置SSL访问Hadoop
- 登陆DataStage服务器,使用keytool命令创建truststore,用于存放来自于Hadoop服务器的SSL安全证书,该truststore名为test.jks, 在/opt目录下
keytool -genkey -alias test -keystore test.jks -storepass test
- 将Hadoop服务器上的SSL证书(例如cert.pem)复制到DataStage服务器
- 在DataStage服务器上通过keytool命令导入证书cert.pem
keytool -import -trustcacerts -alias test -file cert.pem -keystore test.jks -storepass test -noprompt
- 用DataStage自带的encrypt.sh命令加密上面所创建truststore的password,得到加密后的二进制密码(例如{iisenc} iWuRnROgFLbk0H1sjfIc7Q==)
cd /opt/IBM/InformationServer/ASBNode/bin/
[root@IBM-DataStage bin]# ./encrypt.sh
Enter the text to encrypt: test
Enter the text again to confirm: test
{iisenc} iWuRnROgFLbk0H1sjfIc7Q==
- 在/opt目录下创建一个名为properties.txt的文本文件,添加内容如下
password={iisenc}iWuRnROgFLbk0H1sjfIc7Q==
- 修改DataStage配置文件(dsenv),添加以下环境变量
DS_TRUSTSTORE_LOCATION=/opt/test.jks
DS_TRUSTSTORE_PROPERTIES=/opt/properties.txt
- 重启DataStage
5.在DataStage开发客户端中找到File Connector组件
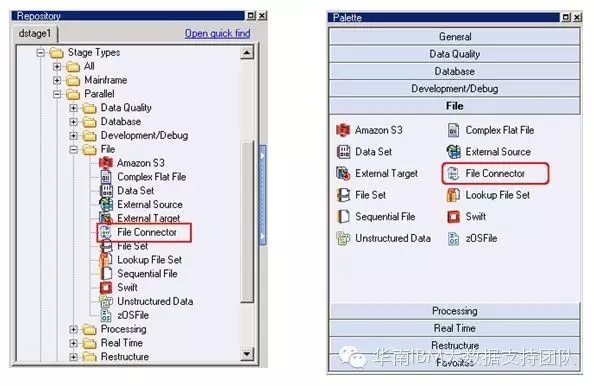
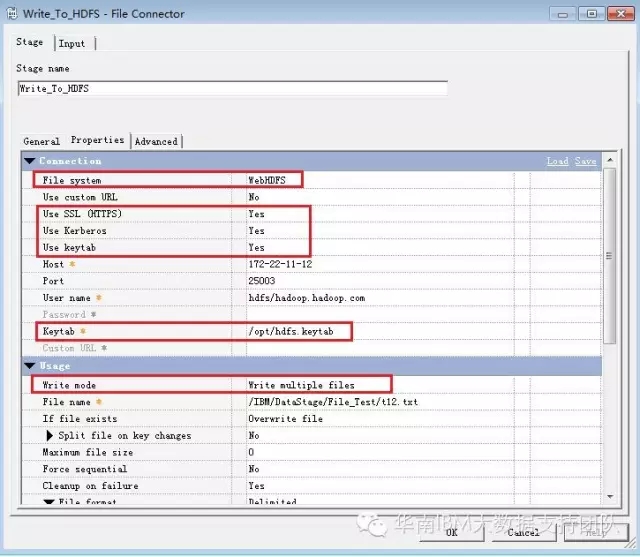
6.配置File Connector组件的属性
- 通过WebHDFS接口访问Apache Hadoop
- 采用Kerberos安全认证(指定Keytab文件)
- 采用https协议及相应端口
- 将源表数据自动拆分成多个文件并行写入HDFS(为提高性能,利用8个节点同时写数据)
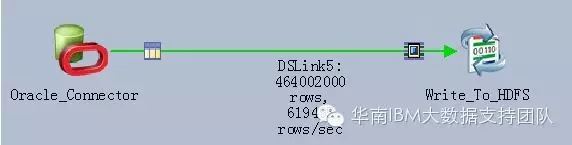
7.运行DataStage作业,可看到数据已成功写入Hadoop HDFS
虽然本次测试是基于虚拟机环境,但DataStage所展现出来的性能依然非常强劲,从Oracle读取4.64亿条记录并写入HDFS,仅需10分钟左右,最高速率达到619495 行/秒。如果增加CPU以提高并行度,性能更可线性增长!
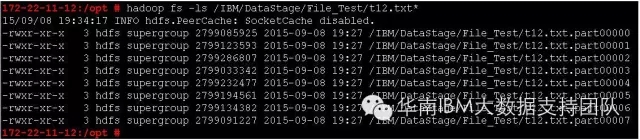
在目标端生成的HDFS文件列表(8个子文件):
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381




发表评论