 023-68661681
023-68661681
 返回
返回

如今大家都在说深度学习。
- 它改变了游戏规则。
- 它改变了你的生活。
- 它改变了所有一切。
- 它将改变这个世界。
人们往往为技术而兴奋。但深度学习是企业用来解决实际问题的工具。仅此而已, 毋庸夸大,也无需贬低。
在本文中,第一部分将首先将介绍深度学习及其基础,作为我们学习的第一部分。第二部分,我们将介绍 Cloudera 数据和机器学习的统一平台,并展示实施深度学习的四种方法。
最后,我们提供六个实用技巧,帮助您的组织开始进行深度学习。
深度学习:一个成熟的技术
机器学习是一组算法和方法用以发现数据中有用的模式。数据科学家有数百种不同的算法可用,包括:
- 线性模型
- 决策树学习
- 基于内核的方法
- 集体学习
- 神经网络
神经网络是一类机器学习技术。 20 世纪 40 年代由神经科学家开发,以模拟人类和动物大脑的行为,数据科学家在许多不同的业务应用中使用它们。它们包含在一些开源软件库和商业软件包中。

如果具有特定的属性,神经网络是有“深度”的,我们将在下文深度学习 101 中进 行讨论。“深度学习”是指数据科学家用来训练和部署深层神经网络的工具和方法。 这些技术可追溯到20世纪80年代;然而,其应用由于计算复杂性和所需资源而滞后。 降低的计算成本,数字化数据的大量涌现和改进的算法使深度学习在当今变得可行。
深度学习的应用
深度学习成为一个有用的工具是当实践者成功地使用它在诸如文件分析和识别、 交通标志识别、医学成像和生物信息学等领域赢得竞争。当今,数据科学家们将 深度学习应用于各种实际问题:
- PayPal,领先的支付系统提供商使用深度学习来检测和防止欺诈。
- Deep Instinct,一个创业公司,使用深度学习来防范网络安全威胁。
- 普渡大学的研究人员展示了一个使用深度学习分析图像并评估灾害损害的系统。
- 劳埃德银行集团利用深度学习来确认致电呼叫中心的消费者身份,减少欺诈 和改善运营。
- 宾夕法尼亚州立大学的科学家和洛桑法兰西社科学院利用深度学习开发出可 以诊断植物和作物疾病的智能手机应用程序。
- Zebra Medical Vision,一家创业公司,通过深度学习诊断乳腺癌。
深度学习是一种成熟的技术,是数字转型的关键驱动力。随着管理人员更多地了 解其成功的应用,对工具和基础架构的需求将会全面激增。
深度学习 101
在本节中,我们将简要介绍神经网络和深度学习。有关更详细的处理,请参阅本 文末尾附加阅读部分中链接内容。
数据科学家使用神经网络指定一个问题作为节点网络,或神经元,以分层布置。 定向图将节点彼此连接。数据科学家使用一个优化算法来找到模型的最优参数集, 例如连接节点的边缘的权重。
人造神经网络中的神经元接受来自其他神经元的数据作为输入。他们用数学函数 处理数据以产生计算结果。数据科学家指定神经元应用于输入数据的功能类型。
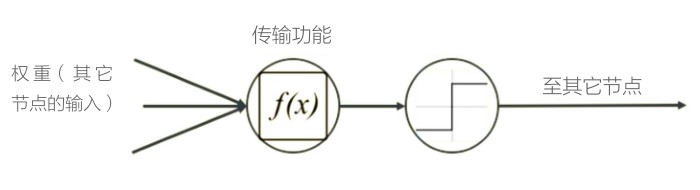
在人工神经网络中,数据科学家将神经元分层布置。人工神经网络中有三种类型 的层。输入层中的神经元接受数据,而输出层中的神经元呈现模型计算的结果。 神经网络的输入和输出层代表真实世界的事实:输入层表示数据向量,输出层表 示我们想要预测、分类或推断的对象。例如,在图像分类问题中,输入是位映射 图像数据的向量,输出是指示图像表示什么的标签 -- 例如“猫”。
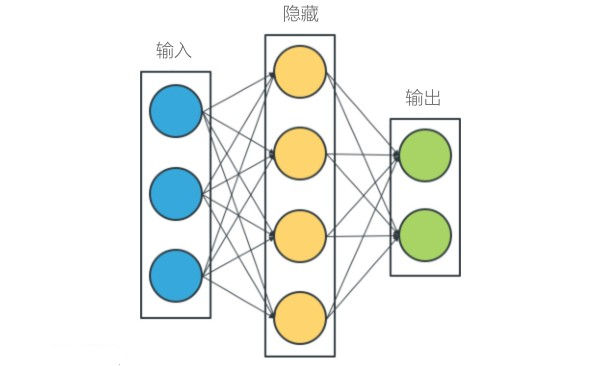
隐藏层中的神经元执行中间计算。隐藏层是不可直接解释的抽象;它们仅仅用于 提高模型的质量。隐藏层可以使神经网络学习任意复杂的功能。
如果人工神经网络具有两个或更多隐藏层,则它是一个深度神经网络。
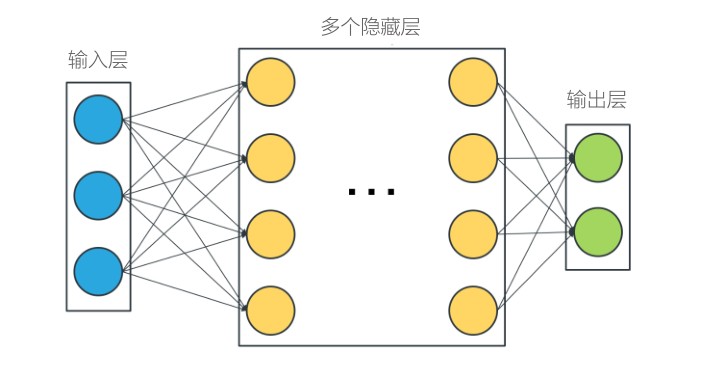
数据科学家使用术语“架构”来描述指定神经网络的不同方法。有许多不同的神 经网络架构,其特征在于拓扑结构、信息流动、数学功能和训练方法。一些广泛 使用的设计包括:
例如,在图像识别中,一个神经元表示图像中的一个像素。在卷积网络中,该神经元可以连接到代表周围像素的神经元,而不是连接到代表图像的远角中的像素的神经元。
- 多层感知器。多层感知器是人工神经网络的基本类型。它们是前馈网络,这意味着一层中的神经元可以接受先前层中的神经元的输入,但是不能从相同层或后续层中的神经元接收信息。
- 卷积神经网络。与神经元完全连接的多层感知器不同,卷积网络中的神经元在本地连接到紧邻区域的神经元,以创建更高级别的特征。这种安排使它们非常适合图像识别任务。
- 循环神经网络。循环网络识别数据序列中的模式,例如时间序列数据、手写、文本、语音或基因组。常规的前馈网络一次从数据中获取一个案例,调整权重以便在处理数据过程中将错误最小化。而循环网络则可以从目前的案例以及前一个案例的输出状态中学习。
还有许多其他类型的神经网络,包括径向基函数网络、限制波尔兹曼机器、深度 信念网络、深度自动编码器、递归神经网络和堆叠去噪自动编码器。
神经网络中的每个数学函数具有一个或多个参数或权重。参数的数量随模型的大 小和复杂程度而增加;在一个极端的例子中,Cloudera 合作伙伴 Digital Reasoning报告了用 1600 万个参数来训练自然语言处理网络。一个大的计算问题需要一个高效的优化算法,如随机梯度下降或 L-BFGS。
数据科学家通过运行具有训练数据的优化算法来训练神经网络。对于预测和推理 问题,训练数据包括具有已知结果的历史示例。优化算法确定一组预测误差最小 化的参数。
大模型需要大量数据。例如,完成 ImageNet 基准测试的微软团队使用了 130 万张图像的数据。
像所有机器学习技术一样,当组织机构将训练过的模型应用于新的信息时,人工 神经网络可以提供业务价值。数据科学家称之为推论。推论与训练正好相反。在 训练任务中,数据科学家使用一系列广泛的历史样本与已知的结果来估计模型的 参数。推论使用经过训练的模型来预测或者推算未知。
深度学习的利与弊
深度学习有两个关键优势,使其与其他机器学习技术区分开。其中第一个是特征 学习。用其他的技术,数据科学家需要手动转换特征以通过特定算法获得最佳结果。 这个过程需要时间,也需要大量的猜测。相比之下,深度学习从多层次的输入数 据中学习更高层次的抽象。数据科学家不用猜测如何组合、重新编码或总结输入。
此外,深度学习还可以检测表面上看不见的变量之间的相互作用。它可以检测非线 性相互作用并近似任意函数。虽然可以使用更简单的方法来适应互动效应,但是这 些方法需要手动指定和数据科学家的更多猜测。深度学习会自动学习这些关系。
特征学习和检测复杂关系的能力往往使深度学习成为某些类型数据的不错选择:
高基数结果。对于诸如语音识别和图像识别等问题,学习者必须区分大量离散类别。(例如,语言识别应用程序必须在英语中区分近 20 万个单词。)数学家称此属性为基数。传统的机器学习技术往往在这个任务中失败;深度学习可以解决成千上万的元素的分类问题。
高维数据。在诸如视频分析、粒子物理或基因组分析等问题中,数据集可以具有数十亿个特征。深度学习可以工作于这样大量的“宽”数据集。
未标记数据。标签提供有关数据包的有价值的信息。例如,图像可以携带标签“猫”。对于无监督学习,深度学习可工作于缺少信息标签的数据(例如位映射图像)。
与其他机器学习技术相比,深度学习也有一些缺点。
技术挑战。深度学习是一个复杂的过程,需要实施者做许多选择。这些选项包括 网络拓扑、传递函数、激活函数和训练算法等。方法和最佳实践才刚刚出现;数 据科学家经常依靠试错来发现凑效的模型。因此,深度学习模式往往比简单和成 熟的技术花费更多的时间。
不透明。通过模型参数的检查,深度学习模型很难或不可能解释。这样的模型可 能有很多隐藏层,没有“真实世界”的指象。数据科学家通过衡量它的预测效果 来评估模型,将其内部结构视为“黑匣子”。
过度拟合。像许多其他机器学习技术一样,深度学习易于过度拟合,倾向于“学习” 训练数据的特征而不将整体推广到整个人群。辍学和正则化技术可以帮助防止这 个问题。与任何机器学习技术一样,组织机构应该对模型进行测试和验证,并使 用独立于训练数据集的数据来评估准确性。
计算密集型。训练深度学习模型可能需要数十亿次计算。虽然可以在常规硬件上 执行此任务,但一些行业分析师建议使用专门的 GPU 加速平台。这个硬件不便宜。 此外,由于对高性能机器的需求,一些客户报告订单和延长的交货时间。
部署问题。深度学习模型是复杂的,这使得它们更难部署在生产系统中。由于模 型的不透明度,组织机构可能需要实施其他措施来向用户进行说明。
看到这里,你对深入学习有没有新的认识呢?如果感兴趣可以关注我们慧都大数据,在后面的学习中我们将介绍Cloudera数据和机器学习的统一平台,并展示实施深度学习的四种方法,以及提供六个实用技巧,帮助您的组织开始进行深度学习。
慧都大数据专业团队为企业提供Cloudera大数据平台搭建,免费业务咨询,定制开发等完整服务,快速、轻松、低成本将任何Hadoop集群从试用阶段转移到生产阶段。
欢迎拨打慧都热线023-68661681或咨询慧都在线客服,我们将帮您转接大数据专家团队,并发送相关行业资料给您!




发表评论