 023-68661681
023-68661681
 返回
返回

Java已经在技术领域工作了20多年,成为最“热爱仇恨”的技术。如果仔细观察各种编程语言,操作系统和数据库,过去几年几乎没有什么变化。随着具有大数据和物联网的新技术空间的发展,我们可以看到很多进步。

但是,Java仍然是Java开发人员许多大数据工具的支柱。实际上,它非常适合大数据,因为Java开发人员的大数据工具的一些核心模块是用Java编写的。更有趣的是,Java开发人员的大多数这些大数据工具都是开源的。因此,它们很容易访问。
在本文中,慧都网将分享Java对大数据工具及其未来的有用性。此外,我们将专注于主要基于Java API的大数据工具。
Java在大数据中的未来是什么?
虽然Java有很多理由不喜欢它,但仍然会有程序员慢慢去使用它,因为他们发现很多理由去学习它。让我们回顾一下人们想要使用它的一些原因:
- 简单性:作为面向对象的语言,Java为开发人员和最终用户提供了非常简单的用户体验。与其他类似的面向对象编程语言相比,Java的内置设计是其最显着的优势。与C ++不同,它已经删除了指针和接口的使用;
- 可移植性:Java运行时可以随时随地运行。因此,您可以在任何硬件和软件平台上运行Java;
- 分配:Java具有堆栈配置功能,有助于快速重建。此外,Java具有垃圾收集和自动内存分发的潜力;
- 分发:Java是高度网络化的。通常,Java会非正式地接收和发送文件;
- 非常安全:Java通过安全编程强制执行强大的安全标准。
现在,让我们看看Java在哪些方面适合于现实中的大数据。
如今,每天产生的数据量呈指数增长。此外,分析如此大量的数据也将在此期间继续增加。批处理数据处理是分析如此庞大数据的现实方法,这主要是使用Hadoop和Spark等开源工具完成的。

有趣的是,大多数开源大数据工具都是基于Java的。其背后的一个关键原因是Java的根源在开源社区中根深蒂固。因此,大量的Java代码是公开可用的,并且利用像Apache这样容易获得的代码基础,Google在制作开源大数据工具方面做出了巨大贡献。
对于最着名的大数据工具Hadoop,Java就是这种语言。因此,Java开发人员很容易学习Hadoop。事实上,学习一些大数据工具几乎与为Java开发人员学习新的API类似。
不仅是Hadoop,而且Pig也是Java开发人员的另一个大数据工具,他们可以轻松学习,因为Pig Latin使用JavaScript。
面向市场的Java开发人员最佳开源大数据工具
毫无疑问,大数据的未来是Java。市场上有许多面向Java开发人员的大数据工具,其中大部分都是Apache开源的。在这里,我们整理了一些主要用于Java开发人员的大数据工具。
1. Apache Hadoop

Hadoop是一个Java子项目,主要用于大数据工具。它是一个Apache Software Foundation工具,后来由Yahoo!捐赠。它是一个免费的,基于Java的编程框架,可在分布式计算环境中处理大型数据集。除此之外,您还可以轻松地将其安装在标准机器群集上。Hadoop在将大量数据存储在一个系统中并对这些数据进行分析的公司中已经非常成功。Hadoop以主/从架构运行。主控制器控制整个分布式计算堆栈的运行。
Hadoop拥有围绕它构建的整个软件生态系统。
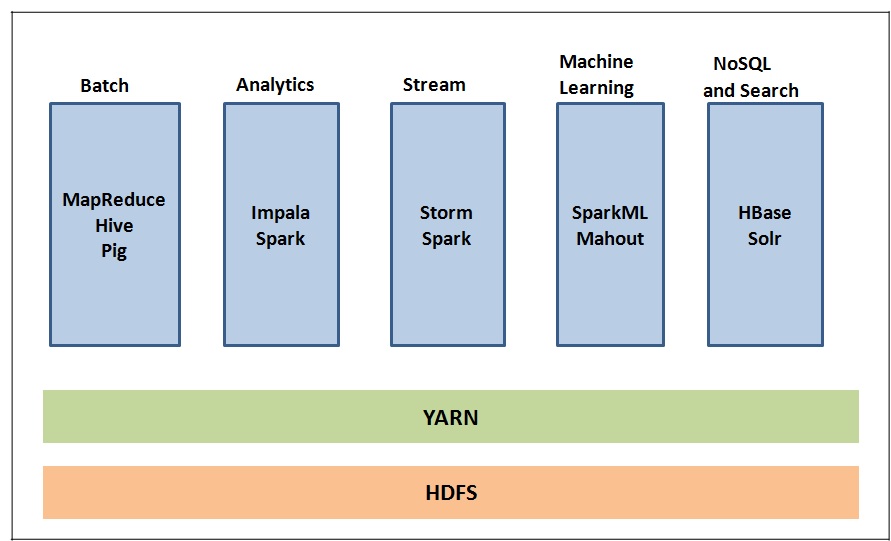
2. Apache Spark

Apache Spark的工作方式类似于Hadoop MapReduce框架,并且比大数据处理的MapReduce更受欢迎。Spark是一个集群计算框架,可以在数千台机器上运行。此外,它可以在这些计算机上的海量数据集上的分布式计算机集群上运行,并将结果组合在一起。Spark站在RDD(弹性分布式数据集)的概念上。
Spark用于大型ETL(提取,转换和加载)操作,预测分析和报告应用程序。Spark程序将执行以下操作:
- 它将一些数据加载到RDD中。
- 对数据执行转换以使其与处理操作兼容 。
- 跨会话缓存可重用数据(使用persist)。
- 对数据执行一些现成或自定义操作。
用于Spark的底层语言是Scala,它本质上是用Java编写的。因此,Java是Apache Spark堆栈的构建块,并且所有产品都完全支持它。Apache Spark堆栈具有广泛的Java API。因此,Apache Spark是Java开发人员易于采用的大数据工具之一,因为他们可以轻松地获取它。
以下是Java开发人员可以轻松用于大数据目的的一些Spark API:
- 核心RDD框架及其功能
- Spark SQL代码
- Spark Streaming代码
- Spark MLlib算法
- Spark GraphX库
有趣的是,Apache Spark已经成为一个完整的生态系统,包含许多子项目,如下所述:
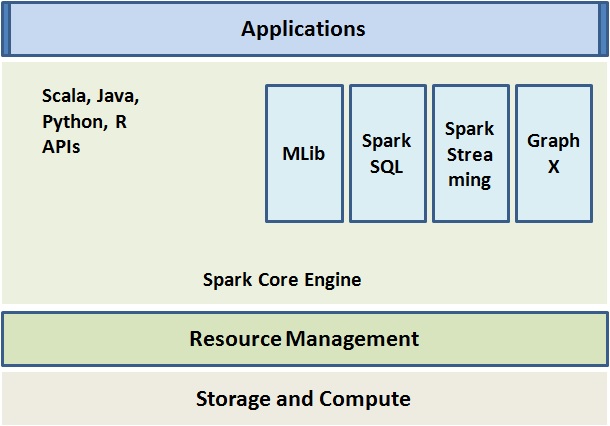
3. Apache Mahout

Apache Mahout是开源大数据工具和流行的Java ML库。它由可扩展的机器学习算法组成,其中一些算法用于:
- 建议
- 聚类
- 分类
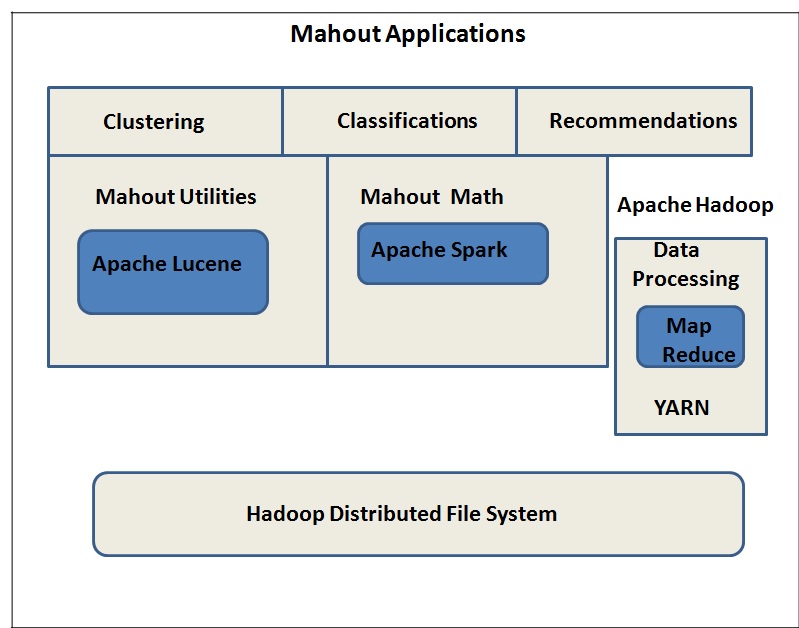
Mahout的一些重要特征如下:
- 它的算法在Hadoop上运行。因此,它们在分布式环境中运行良好
- 它内置了几种ML算法的MapReduce实现
4. Java JFreechart
数据可视化是大数据分析中的一项重要任务。大数据处理大量数据; 因此,通过查看原始数据来找出趋势是具有挑战性的。但是,当在图表上绘制相同的数据时,它变得更易于理解并且易于识别数据中的模式和关系。
JFreechart是Java开发人员的流行开源大数据工具之一,它使用Java内置的库来帮助制作图表。
我们可以在这个库的帮助下构建不同的图表来可视化数据,例如:
- 饼状图
- 条形图
- 单个和多个时间序列图表
- 折线图
- 散点图
- 方块图
- 直方图
JFreechart不仅可以在图表中构建轴和图例,还可以使用鼠标在图表中自动缩放功能。但是,它对于简单的图表可视化很有用。
5. Deeplearning4j

Deeplearning4j是一个Java库,用于构建不同类型的神经网络。此外,我们可以将它与Apache Spark集成在大数据堆栈上,甚至可以在GPU上运行。这是Java开发人员唯一的开源大数据工具,它们拥有主要的Java库,并且有许多专注于深度学习的内置算法。此外,它有一个非常好的在线社区,有良好的文档。
特征:
- 分布式GPU和CPU
- Java,Python和Python API
- 支持微服务架构
- 可在Hadoop上扩展
- GPU支持在AWS上扩展
6. Apache Storm

这是Java流应用程序和Java开发人员流行的大数据工具的理想选择。
Apache Storm有许多优点,其一些主要功能是:
- 方便使用的
- 免费和开源
- 适用于小规模和大规模实施
- 高度容错
- 可靠
- 非常快
- 执行实时处理
- 可扩展
- 使用运营智能执行动态负载平衡和优化
Apache Storm架构有两个主要组件:
- 主节点(Nimbus)
- 工人节点(主管)
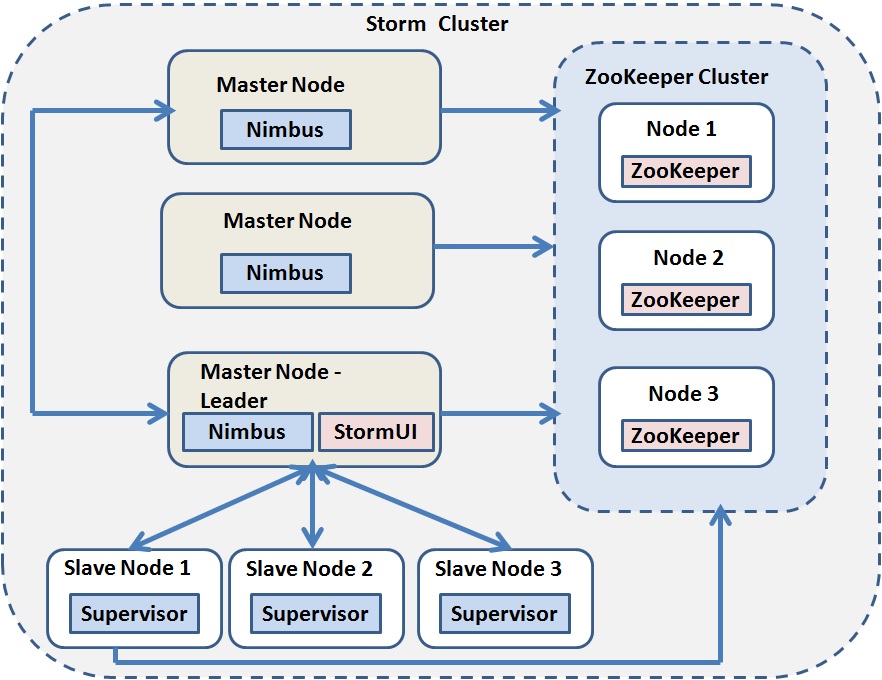
单个工作节点运行一个名为“Supervisor”的守护进程.Nimbus控制工作节点,并且监督节点监听分配的工作并相应地启动和停止工作进程。 每个工作进程都与拓扑的子集相关联,该拓扑由许多工作进程组成。Nimbus和Supervisors之间的整个协调是使用Zookeeper集群执行的。
总结
随着大数据每天都在不断发展,新的工具正在崭露头角。毫无疑问,在Java开发人员的大数据工具中,Hadoop是最好的,相当于大数据的“圣经”。因此,在您学习任何其他大数据工具之前,了解Hadoop是必须的。
与此同时可以拨打慧都热线023-68661681或咨询慧都在线客服,我们将帮您转接大数据专家团队,并发送相关资料给您!




发表评论