 023-68661681
023-68661681
 返回
返回

多元回归是六西格玛管理中常用的一统计工具,它可以帮助考察多个x对y的影响,并建立可以用于预测的回归方程。而今天将基于Minitab 19向大家介绍机器学习下的多元回归。Minitab中已经引入很多机器学习的算法,在Minitab 19中还加入了CART分类树与CART回归树算法,但是今天的重点是多元回归。
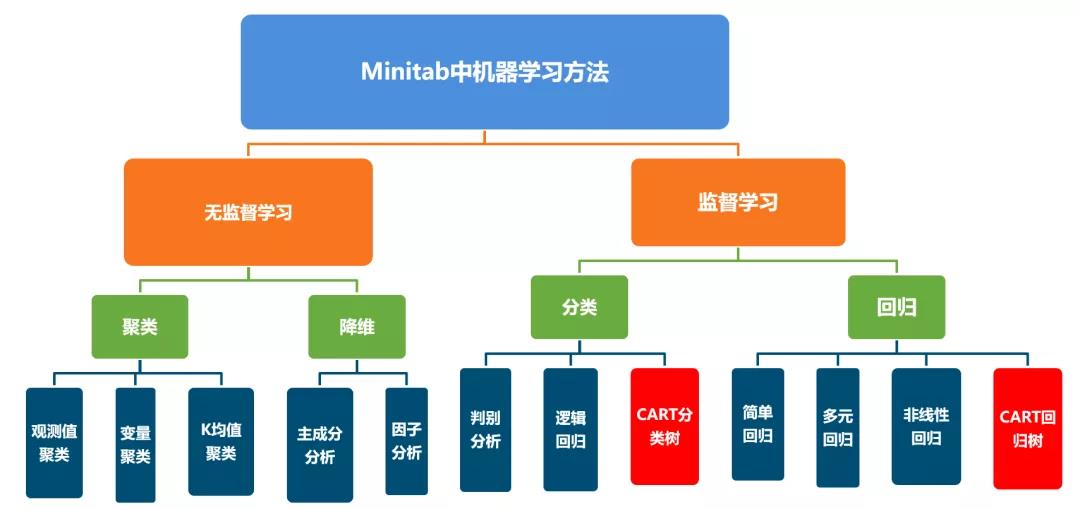
什么是好的模型?
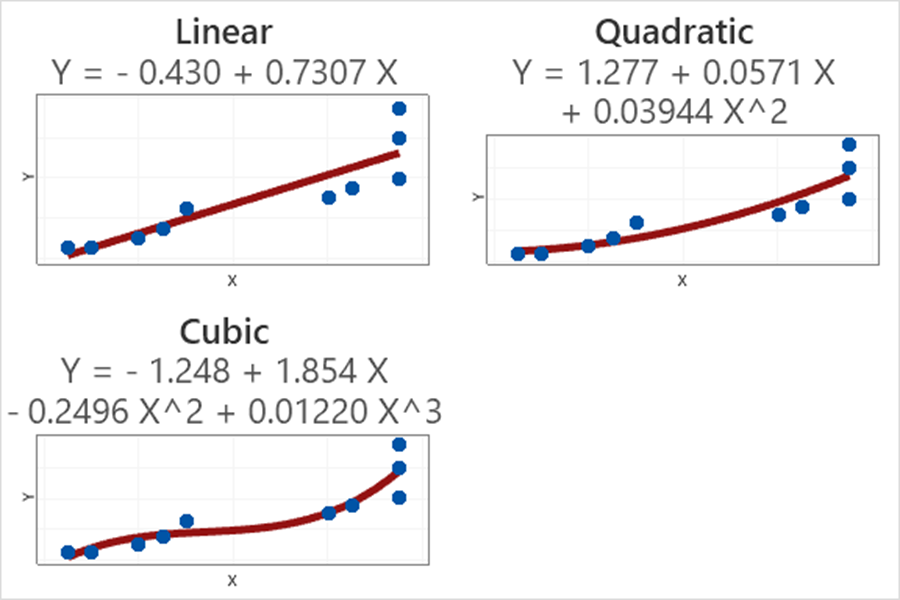
在建模的时候最不愿意看到两种情况:过度拟合和欠拟合。使用与拟合模型相同的数据来评估模型,经常会导致过度拟合,如下图。
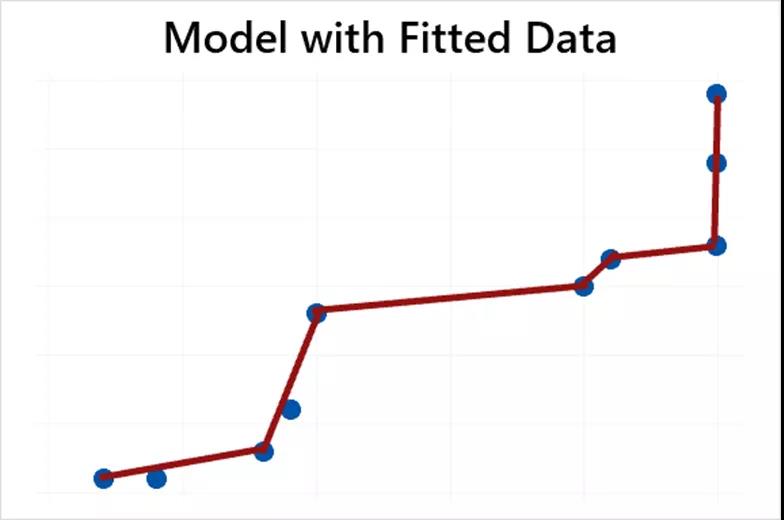
而这种过度拟合的模型如果用来预测的话,效果往往不好。
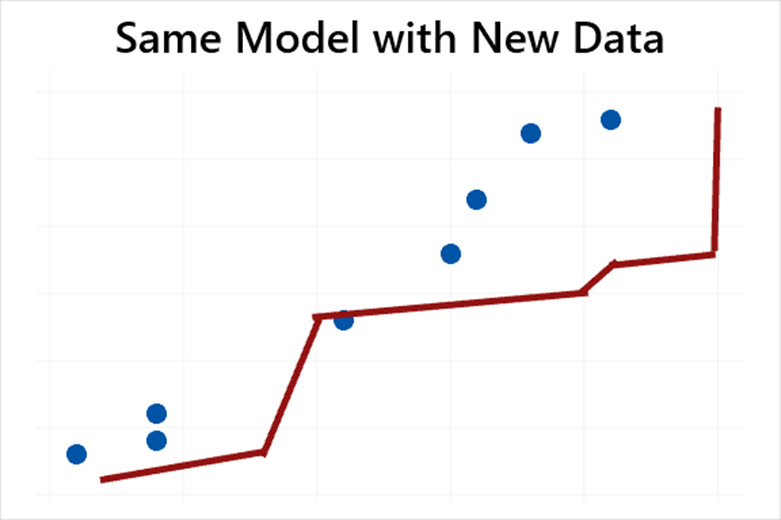
那么什么才算一个好的模型呢?一个好的模型需要在高方差(过度拟合)和高偏差(欠拟合)之间找到一种权衡。
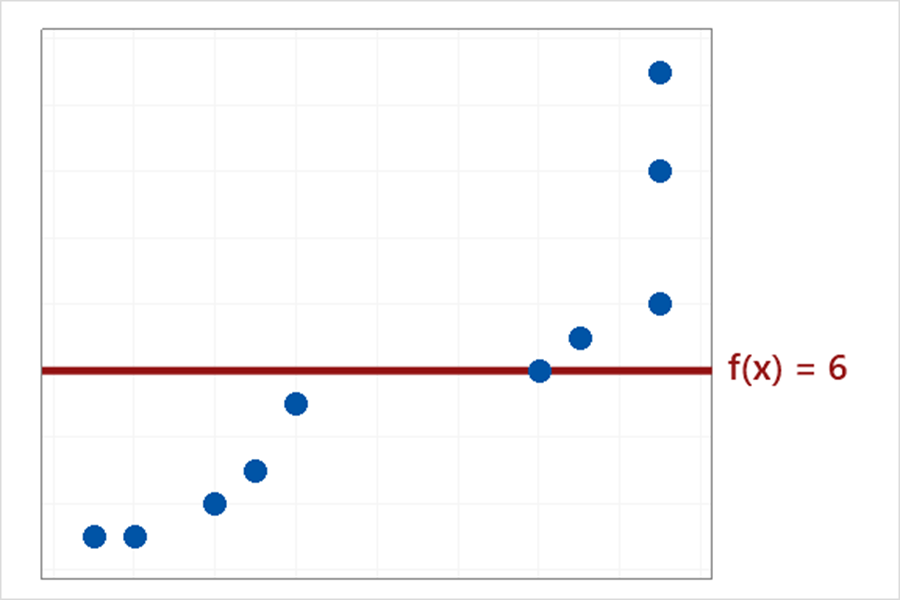
上图就是由于模型太简单导致存在高的偏差。
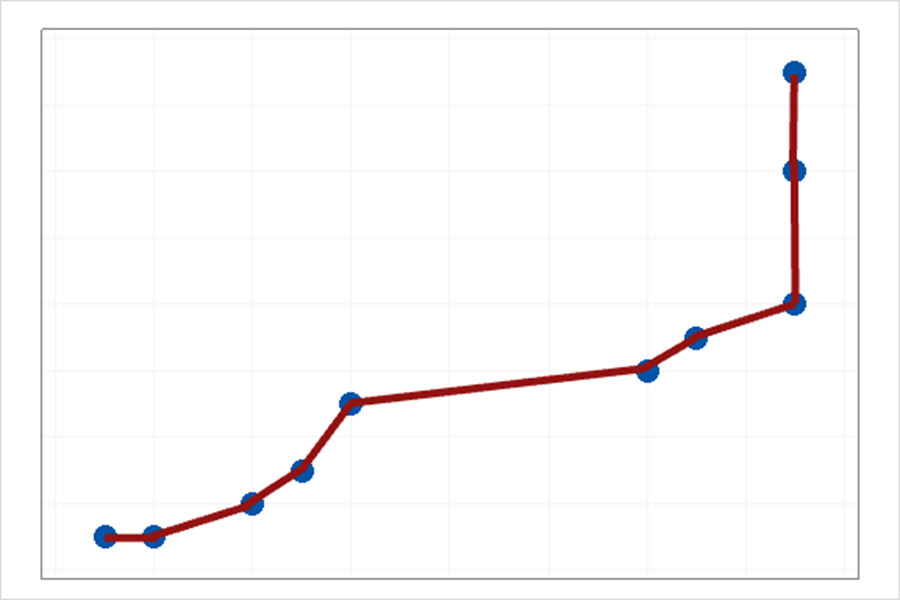
上图就是由于模型过度拟合导致存在高的方差(为什么说高方差呢?大家试想一下挪动一点试试看)。
什么是“验证?
那么如何去找到“高偏差”与“高方差”之间的权衡呢?这就需要用到“验证”法了。
机器学习下的多元回归把数据分为两大类:训练集和测试集。训练集用来创建模型,而测试集来评估模型的性能。这样就可以来权衡过度拟合和欠拟合的模型。
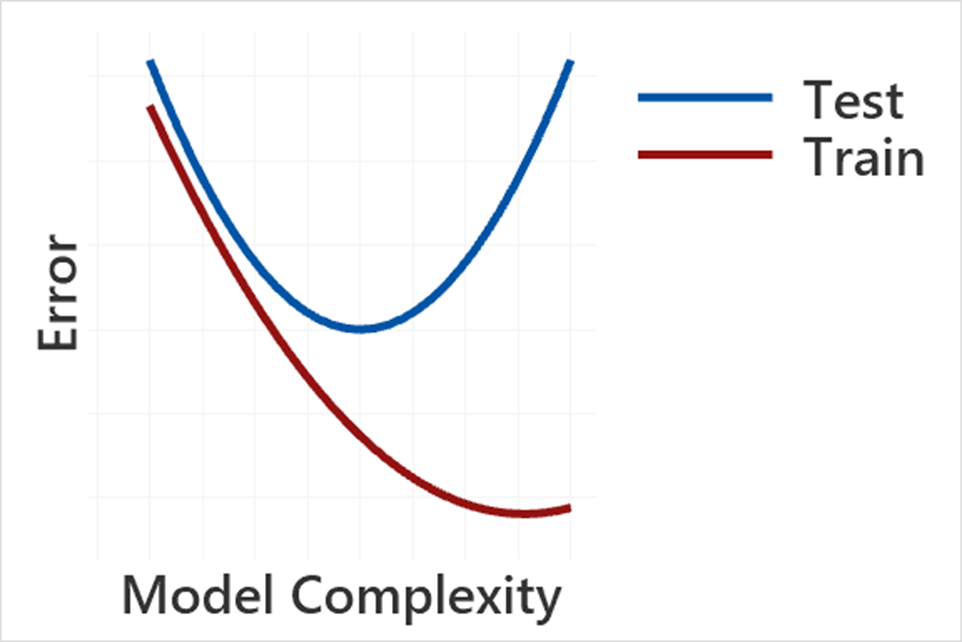
从上图中我们可知,用训练集来建模时,模型越复杂模型误差越小,但再来看看测试集你会发现当模型复杂到一定程度,它的误差会随着模型复杂度的增加而增大。也就是说,太简单和太复杂的模型都不能很好的用来预测。这是如何做到的呢?这就要来说说机器学习中的“验证”法了。
在Minitab 19中的回归中,加入“验证”按钮,丰富了验证的方法。
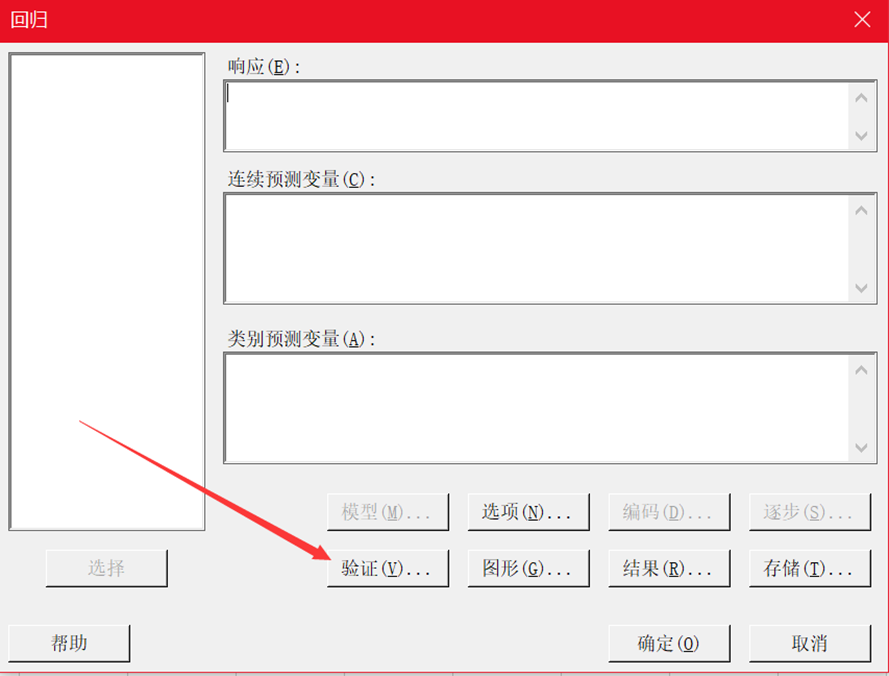
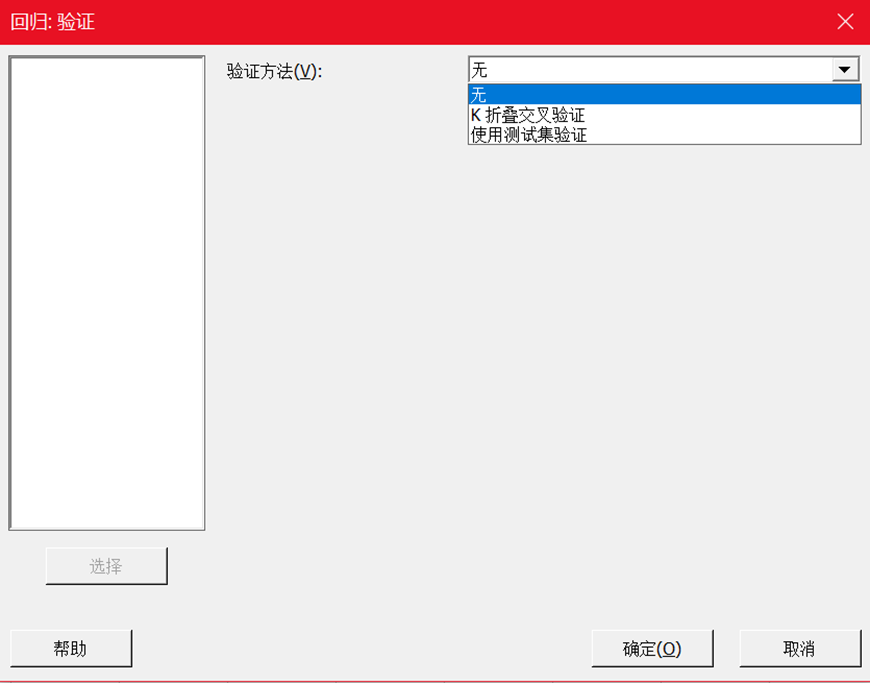
验证法一共有三种:留一验证法、测试集验证法和K者交叉验证法,下面我们一起来看看三者之间的区别。
留一验证法
这种方法正如其名,留一留一,就是留下一行yi,再用其他所有数据来建模,得到模型后再把留下来这一行代入得到的模型就会得到对应的拟合者,其过程如下所示:

接下来,我们计算预测的残差平方和(Predicted Residual Sum of Squares)
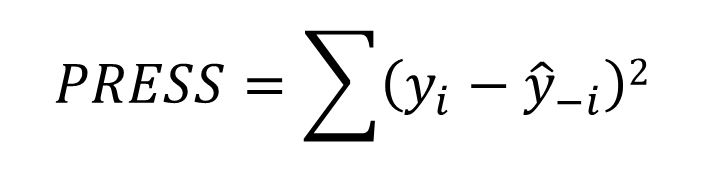
有了PRESS就可以来计算R-sq(预测)了,到这里是不是很熟悉了。
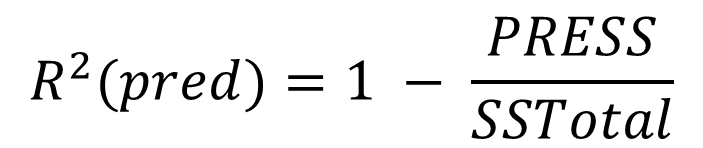

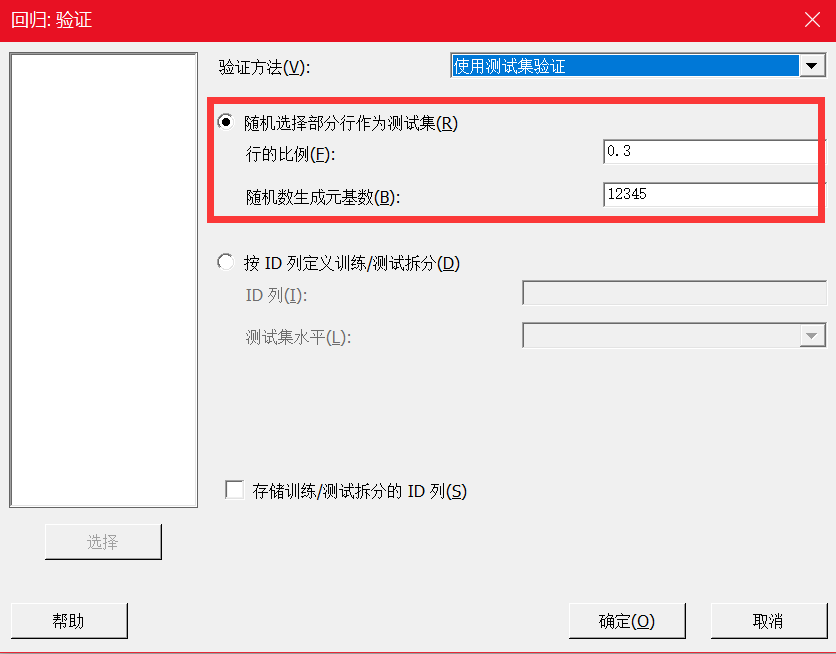
测试集验证法
随机保留一定比例(Minitab 19默认保留30%)的数据(测试集),用剩余的数据来拟合模型(训练集)。
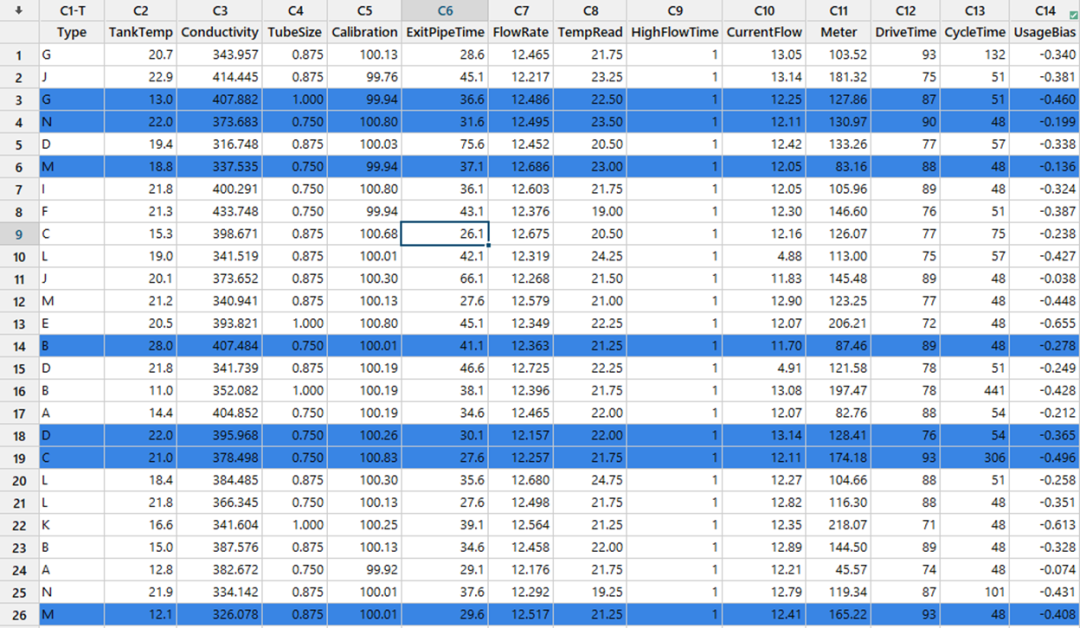
用测试集数据计算误差,基于测试集数据的误差统计汇总信息选择模型。
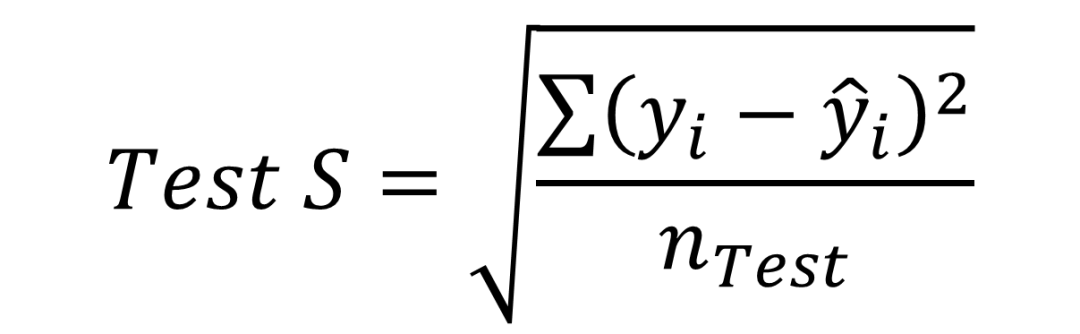
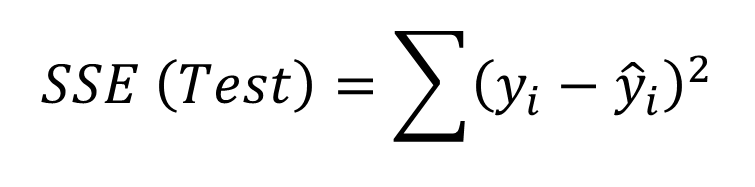

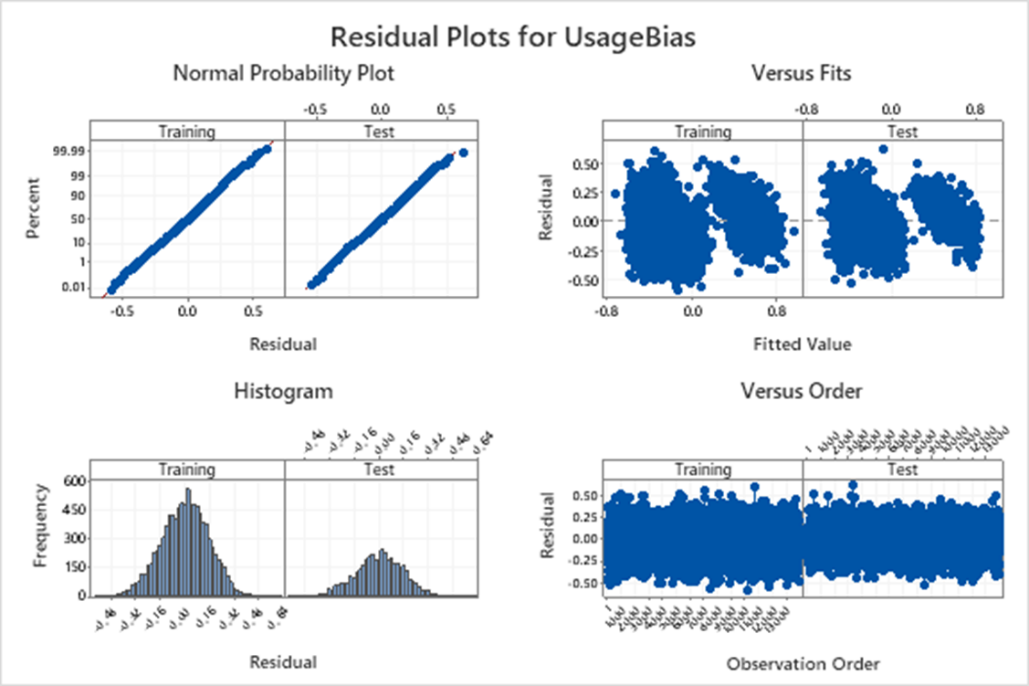
另外,此时的残差分析也有点不同。
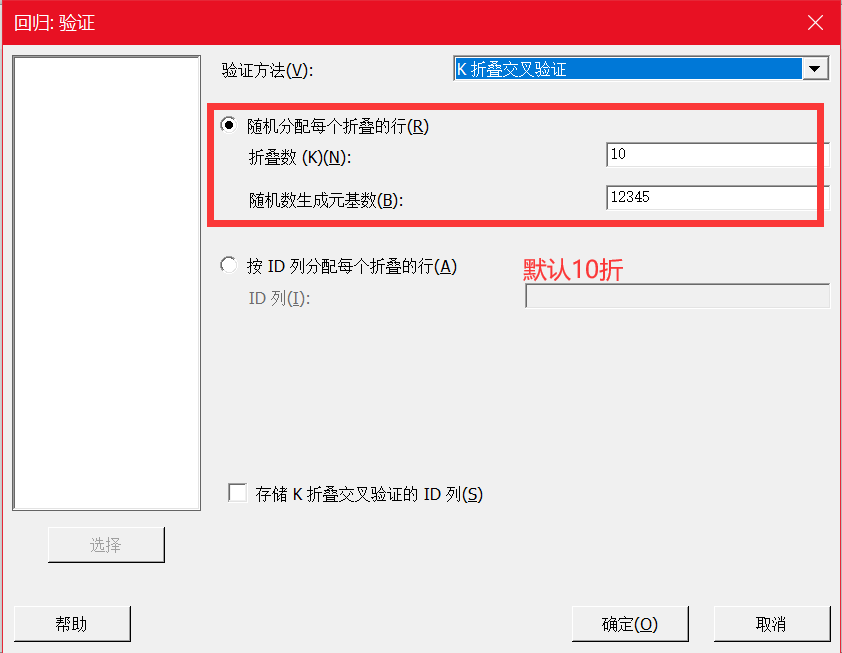
K折交叉验证法
将数据拆分为K个子集或份,以其中一份为测试数据,其它K-1份用于训练数据来拟合模型。使用测试数据计算误差,重复k次,每次忽略一份,基于测试数据误差统计汇总信息选择模型。
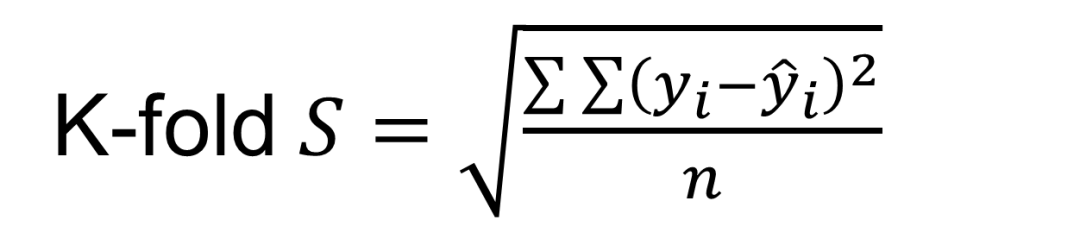

总结
这三种验证方法,留一法比较实用于小样本,测试集验证和K折交叉验证比较实用于大样本(在Minitab 19的CART分类树和CART回归树中,当数据行数小于等于 5000 时,K 折交叉验证方法为默认方法)。另外,在Logistic回归中仅使用测试集验证法。
最后,如果您感兴趣,不妨再去试试Minitab 19中的逐步回归,您也会有新发现哦!
Minitab是做质量分析的工具,不知道您是否有产品质量这方面的困扰呢?不妨试试产品质量分析及预测方案吧!点击咨询在线客服



发表评论