 023-68661681
023-68661681
 返回
返回

相信接触数据管道的公司都很困惑到底应该选择ETL还是ELT?有人认为ELT可以根据数据的分布情况进行并行处理优化,它更好;也有人认为ETL可以分担数据库系统的负载,可采用单独的硬件服务器部署,所以它更好,到底谁好一直争论不休,那么希望看完本文能平息这一争端。

回归本源
任何数据管道的流动的目的只是将以规定的格式和结构存储的数据从一个地方移动到另一个地方。数据的源头称为源,目的地称为目标,有时也称为汇。有两种模式描述了这个过程,但都没有规定持续时间、频率、传输技术、编程语言或工具。这两种模式如下:
ETL--代表提取、转换、加载,确切地描述了流水线的每个阶段所发生的事情。首先从源头提取数据,然后以某种方式进行转换。最后,数据子集被加载到目标系统中。
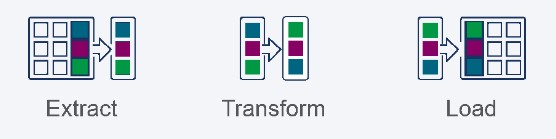
ELT - Extract, Load, Transform模式类似。管道开始时,再次从源数据中提取一个数据子集,但随后立即将其加载到目标中。最后一步执行数据转换。
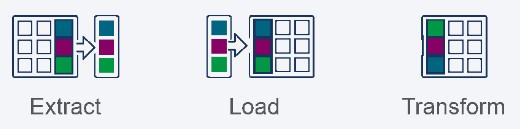
很明显,这两种模式之间的唯一区别是,当你执行数据转换时。请注意,这两种模式都没有规定转换是发生在数据传输之前、期间还是之后。例如,让我们检查一下ETL模式。
下图说明了数据子集是在转换和最终加载发生之前通过线传输的。
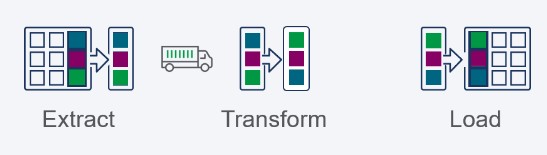
同样的道理,在传输和最终加载之前,提取和转换数据子集也同样有效。
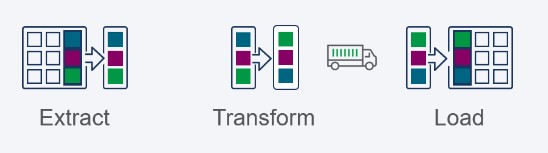
在现实中,厂商的实现往往决定了数据传输操作的顺序和优先性。事实上,前面提到的许多实施细节(如频率等)也高度依赖于供应商。
ETL和批处理
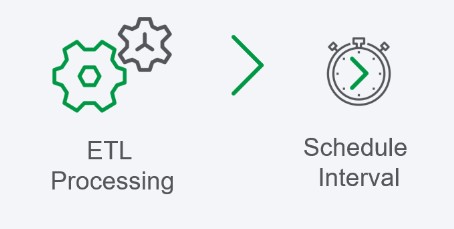
一般来说,ETL流程按照预定的时间表运行,例如每分钟、每小时、每天或每周,这取决于用例。请注意,ETL管道也可以响应外部触发器或事件而运行,但这种情况不太常见。
一个预定的ETL过程被称为以批处理模式运行,其频率往往由以下约束条件决定。
- 所需数据的及时性
- 提取数据的时间
- 转换的持续时间
- 传输数据的时间
- 执行加载的时间
- 批次之间的交易量
总的来说,这个过程很好用,但当数据量和ETL处理时间超过所需的时效性时,就会出现困难。例如,一家银行可能需要每10分钟更新100万笔交易的数据仓库,但提取、转换和加载批处理需要15分钟。将频率延长到20分钟不是答案,因为数据量也分别增加到了200万行。
它们是做什么的?
ELT、CDC和实时
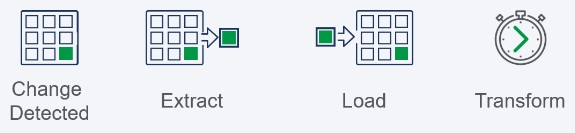
银行的备用策略是重新思考流程,并在不同步骤发生时重新安排优先级。如果我们假设提取、传输和加载数据的时间与之前相同,那么使用ELT可以让后端进行转换,可能是在更多资源可用的时候。
这种模式可以通过添加变更数据捕获(CDC)进一步增强。CDC不像ETL那样按批处理计划运行,而是在数据源发生变化时每次都会被触发。因此,在我们银行的例子中,ELT流程为每一笔交易运行,并且通过电报传输的数据量很少。不需要等待处理一百万行的数据。实际上,提取和加载过程是实时发生的。
然后,银行可以选择安排一个批量转换过程,或者推迟转换,直到数据被消耗。通常情况下,我们发现客户会采用这两种选择。
此外,近年来数据的数量、速度和种类都在大规模增长,ELT在很多情况下已经取代ETL成为数据移动的事实模式,尤其是在云数据迁移、数据仓库和湖泊摄取以及ML Ops--利用机器学习实现数据管道的持续交付和自动化等场景下。
结论
在这篇文章的开头,我们争论了对于数据管道来说,ETL还是ELT是更好的模式,最后得出了 "这要看情况 "这个不满意的答案。虽然传统上ETL一直是数据集成的主力军,然而事实是,时效性很重要,而ETL却步履蹒跚。因此,如果你的分析或机器学习项目需要实时的数据,那么ELT是首选模式。
如果您想使用屡获殊荣的ELT解决方案实时移动数据,请选择Qlik Data Integration进行测试。



发表评论