 023-68661681
023-68661681
 返回
返回

当技术团队开始将现有系统和EDH(企业数据中心)集群拼接在一起时,通常会采用以下常见的设计模式:将文件转储(通常为CSV格式)定期上传到EDH中,接着进行解压缩,转换为最佳查询格式,然后隐藏在HDFS中,在这里各种EDH组件都可以使用它们。
当这些文件转储很大或很经常出现时,这些简单的步骤可能会显著减慢数据撷取管道的速度。这种延迟的一部分是不可避免的;由于物理限制因素,跨网络移动大文件是非常耗时的一件工作,并且提升其速度是非常困难的。然而,上述的其他基本数据摄取工作流程通常可以进一步改进。

在这里我们向大家展示一个EDH中文件处理的简单使用案例:在 hdfs:///user/example/zip_dir/ 中存在一个CSV文件目录,但是该文件目录已压缩为原始 *.zip文件。为了使它们可用,需要将它们提取并压缩成单个文本文件,该文件将放在 hdfs:///user/example/quoteTable_csv/中。
由于这些都是CSV文件,我们假设每个CSV文件在其第一行都有一个简单的标题。执行此操作的一个常用方法是:在EDH的“边缘节点”上执行一条类似于下面详述的脚本程序 - 该“边缘节点”是集群中的一个节点,其具有所有必需的配置文件和应用程序库,以便与集群的其余部分进行交互。有关我们用于这些案例的边缘节点和集群的详细信息,请参见本文以下部分中标题为“集群详细信息”的章节。
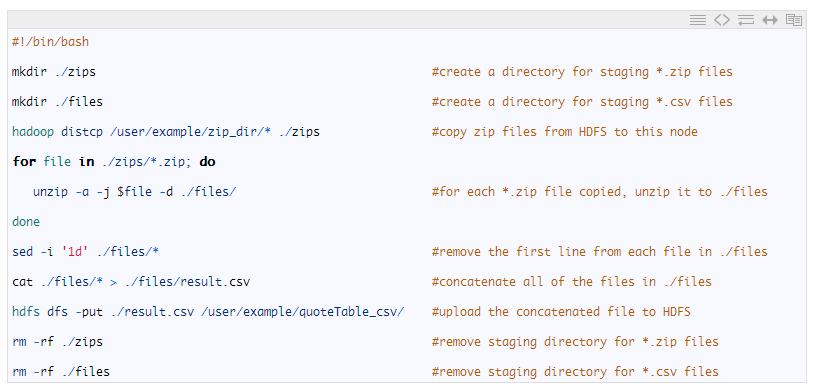
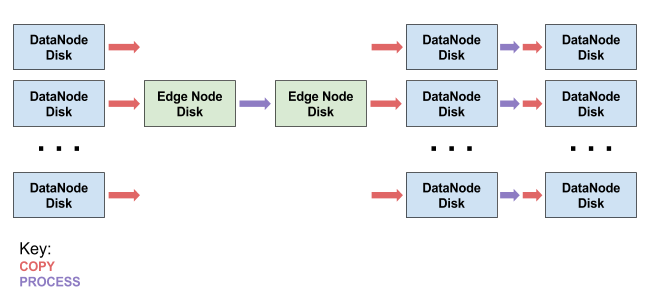
下图显示了此解决方案的基本流程,其中箭头表示要将数据复制到位于新位置上的文件中。换句话说,块之间的每个箭头表示数据从左侧块复制到右侧块所需的时间。紫色箭头表示对数据执行计算的时间,而红色箭头表示简单地复制数据所需的时间。
- DataNode Disk DataNode(磁盘)
- Edge Node Disk(边缘节点磁盘)
- Key (箭头)
- Copy (复制)
- PROCESS (处理)
虽然这个解决方案是非常常见且容易实现的,但显然存在一定的瓶颈。在我们的示例集群中,此脚本程序耗费了125秒的时间来完成包含10,000,000条记录的zip文件。
更优的解决方案
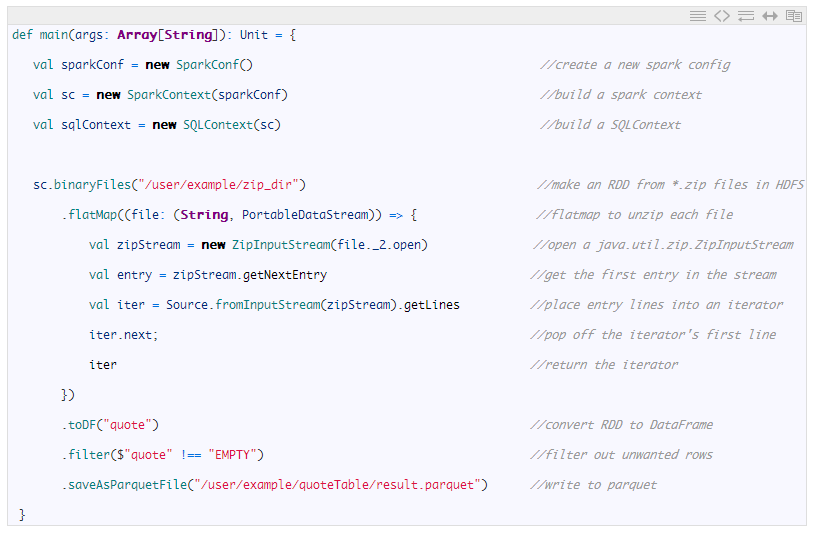
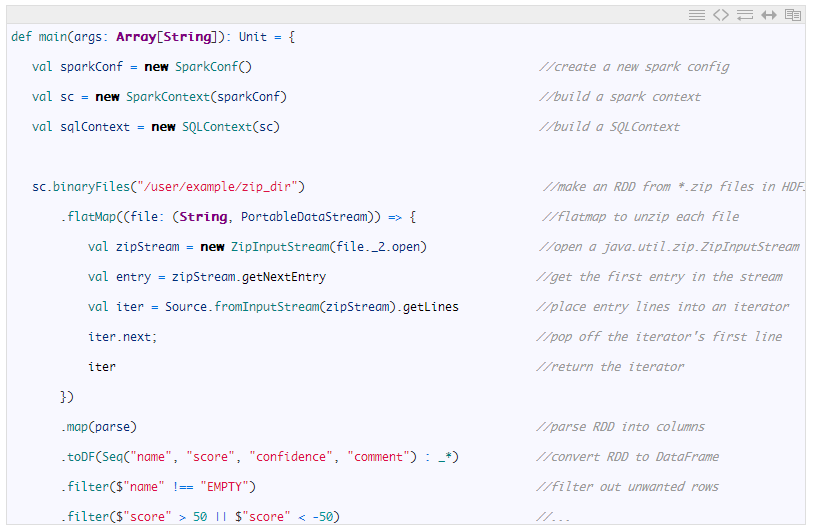
通过利用Spark进行分发,我们可以使用相同数量的代码更快地获得相同的结果。通过在整个过程中将数据保存在HDFS中,我们能够在大约36秒的时间内撷取与之前相同的数据。让我们来看看Spark代码,其形成了与上面显示的bash脚本相同的结果 - 注意该代码和本文中引用的所有代码的更高参数化版本可以在下文中的“参考资料”章节找到。
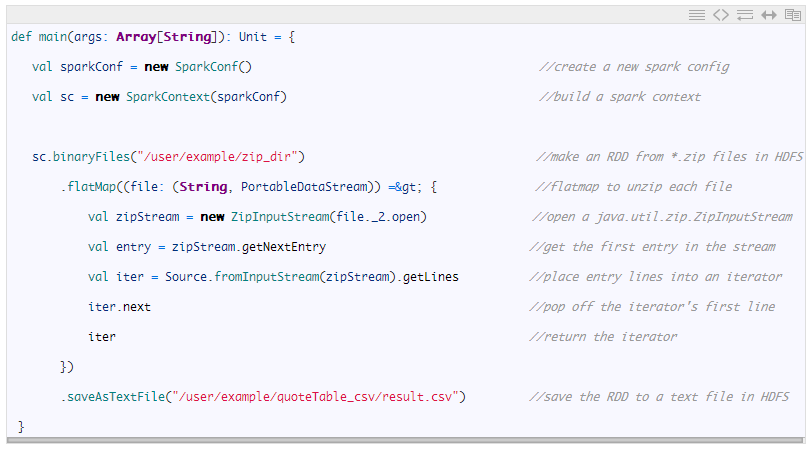
提交到集群的程序如下图所示:
如下图所示,通过将这个数据撷取工作载荷从边缘节点脚本程序移动到Spark应用程序,我们看到了显着的速度提升 - 在示例集群上解压缩文件所需的平均时间减少了35.7秒,这相当于速度提升超过300%。下图显示了在多个不同输入上运行这两个工作流程的结果:
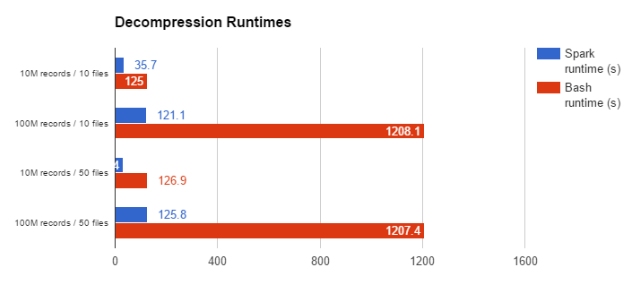
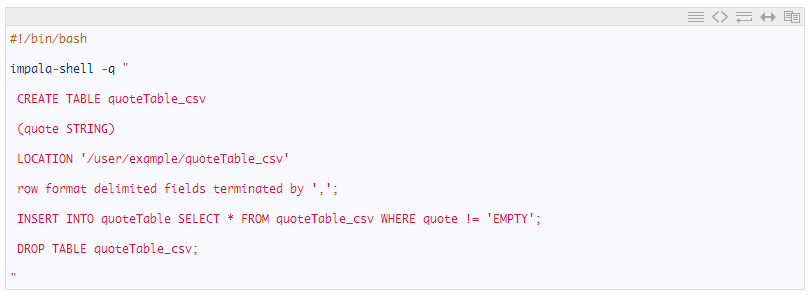
对于较大的数据集而言,Spark工作流程与简单的bash工作流程相比一般会提升超过900%的速度。现在,我们将检查一个更加复杂的工作流程,其中涉及解压缩文件的处理。在此工作流程中,来自 hdfs:///user/example/zip_dir/ 的压缩 *.csv文件的行将被解压缩并放入Impala表quoteTable中,该表是由位于hdfs:///user/example/quoteTable/的parquet 文件提供支撑的。此外,根据数值将过滤掉其中某些行。我们先前的bash脚本程序仍然可以继续使用,同时调用Impala将*.csv文件转换为parquet文件:
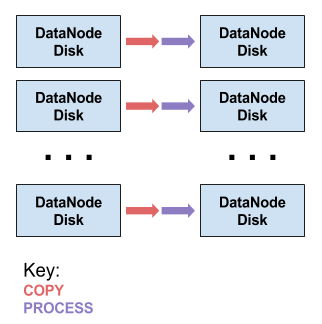
尽管Impala执行数据转换和过滤的速度相当快,但这种常见的使用模式仍然需要在HDFS之间复制数据。此问题如下图所述,其中描述了这个新的工作流程:
在我们的数据集上运行上面定义的bash脚本程序138.5秒后,通过比较,我们可以修改我们的Spark作业,通过新的功能重写下面的内容,以此实现同样的效果:
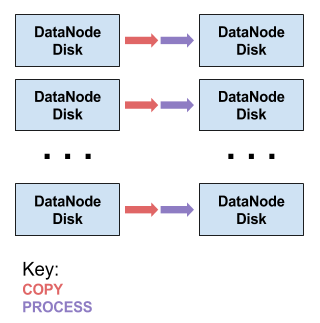
图中,这个程序与之前的看起来没有任何区别 - 其中箭头“处理”表示更密集,因为其现在包括过滤和转换以及解压缩操作,但是数据不会被再次写入磁盘。另外还有一个好处,过滤掉的数据不会再被复制到磁盘中,而在我们以前的解决方案中不是这样的。
这个Spark作业在64秒内完成,比基于bash脚本程序的解决方案速度提升了200%。对于较大的100M记录数据集而言,我们的Spark作业速度提升超过300%。我们集群中的数据节点每个只包含2个磁盘,并且每个磁盘有足够的内核支持2个单核执行器。通过使用功能更为强大的数据节点,对于像我们这样的工作载荷而言,Spark对于将多线程写入到parquet文件的支持将使其显示比Impala更大的优势。即使是小型集群,Spark展现出的性能优势也是非常明显的:
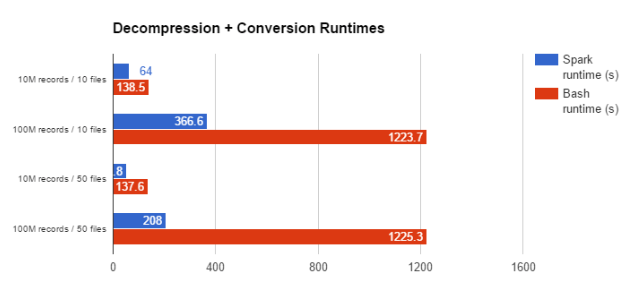
- Decompression + Conversion Runtimes (解压缩+转换运行时间)
- Spark runtime (s) (Spark运行时间 (s))
- Bash runtime (s) (Bash运行时间 (s))
- 10M records / 10 files (10M记录/10个文件)
一旦Spark将信息加载到DataFrame中,就可以很容易地在内存中执行任何额外的转换操作。在我们的最后一个示例中,让我们想象一个更复杂的流程管道:我们的数据集中现在包含多个列,其中两个采用引号括起来的字符串列可能包含我们的分隔符(‘,’),其中一个需要括起来的整数列在-100和100之间,另一个是需要平方的双列,并且需要应用几个简单的过滤器。我们将使用Apache Commons CSV库来简单地处理更复杂输入的解析。这个过程的Spark实现如下所示:
由于涉及到写入更简洁的数据类型,其最终测试的完成时间比上一个测试明显快了很多。我们的Spark工作流程在52秒内就完成了,与传统解决方案相比应用了少得多的代码,传统解决方案需要148秒才能完成。下图显示了上例中使用的相同数据集所需的运行时间:
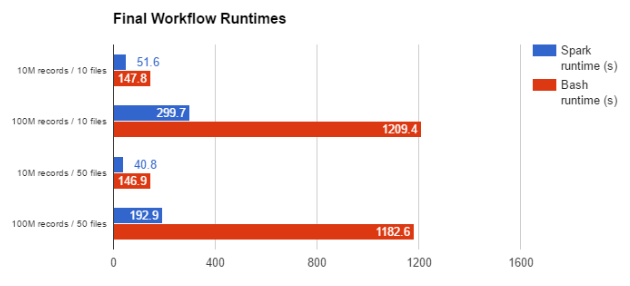
如上图所示,与使用bash和Impala的更直观的解决方案相比,在我们的示例中数据撷取工作流程明显速度更快,并且随着输入数据量的增加这种速度差异会变得更大。通过充分挖掘Spark的潜力来简明地执行分布式计算以及以分布式方式执行定制化或第三方代码,我们在最后一个示例中的数据撷取过程速度提升率超过600%。
现在你已经了解了其基础知识,那么就赶快思考一下如何利用Spark加速您的ETL吧!
集群详细信息
- 硬件: 6个EC2c3.xlarge节点
- CDH版本: 5.8.2
资源
- 脚本程序
- Spark
- 结果
欢迎拨打慧都热线023-68661681或咨询慧都在线客服,我们将帮您转接大数据专业团队,并发送相关资料给您!




发表评论