 023-68661681
023-68661681
 返回
返回

特性:
- 快速高效
- 完全的分布式SQL查询处理引擎。
- 高级查询优化,如基于成本和渐进式的查询优化。
- 合理的数据集上进行交互式分析。
- 可伸缩
- 容错性与长时间运行查询的动态调度。
- 比主内存更大的数据集核外算法。
- 可兼容
- 遵从ANSI / ISO SQL标准。
- 支持Hive MetaStore 的访问。
- 支持JDBC驱动。
- 支持各种格式文件。如CSV、 JSON、 RCFile、SequenceFile、 ORC以及 Parquet。
- 简单
- 用户定义函数
- 交互性的外壳
- 方便的备份/恢复功能
- 异步/同步Java API
体系架构:
Tajo采用了Master-Worker架构,Master-Worker-Client之间的RPC通信是使用Protocol buffer + Netty来实现的,具体如下:
1) TajoMaster:为客户端提供查询服务和管理各个QueryMaster(也可以说是Tajo Worker),解析Query并协调QueryMaster,目前还内置了catalog服务器。大致可以分为四个组件:Cluster Manager、Catalog、Global Query Engine以及History Manager。
- Catalog 的工作是管理诸如tables、schemas、partitions,functions,indices及statistics等各种metadata。这些元数据信息一般都是Global Query Engine来操作,为了低延迟考虑跟hive一样都是存在RDBMS(目前支持Derby和MySQL),默认是保存在内置的Derby数据库中。后面可能会考虑使用hive的HCatalog来完成这块功能。
- Cluster Manager 主要是管理集群中各个节点之间的通信信息及资源(内存/CPU/Disk)信息,每个节点定期发送资源信息,交给Master来管理将用于查询计划的分配等,这一块是依赖Yarn的ResourceManager来管理。
- Global Query Engine 当一条query提交到master,GQE就会依据表的metadata以及集群资源信息(依赖于Catalog和Cluster Manager两个模块提供的信息)生成一个全局的查询计划。对于一个分布式执行环境,全局的查询计划将会被分片,划分成各个查询单元分配给各个worker去执行,在这些worker执行过程中GQE会监控每一个查询单元的运行状况并实时去优化和容错。在这一块目前的语法解析是用ANTLR 4生成AST(抽象语法树),这个以后可能会使用Tenzing的SQL Query Engine。
- History Manager 收集各个query job状态信息包括查询语句,划分的查询单元等,通过web ui(默认端口号:26080)可以查询。
2) QueryMaster:负责一个query的解析、优化与执行,它参与多个task runner worker协同工作,完成一个query的计算。每个Query Master可以生成多个TaskRunner来执行master的查询单元,这些task runner都是由yarn中的NodeManager来管理。
3)Tajo Worker 每个节点就是一个worker角色,每个worker包含存储模块管理和一个Local模式的Query Engine,这个local模式的Query Engine就是来接受master分配的查询单元。每个查询单元包含一个逻辑查询计划和一个分片(输入数据关系的信息块),在执行过程中worker定期向master汇报查询进度和资源信息,master可以很灵活地面对非异常的错误。
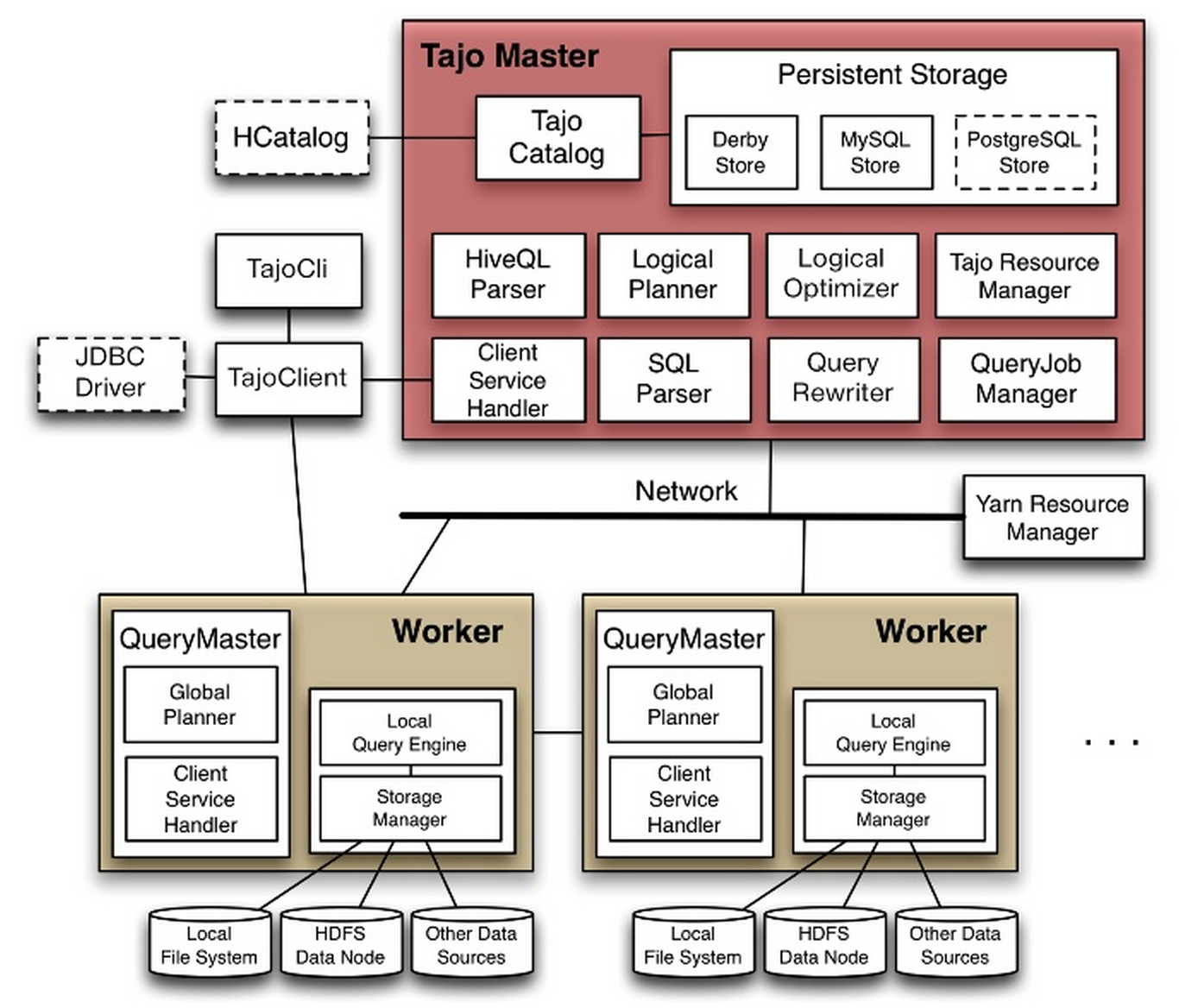
如上图所示,Tajo采用传统数据库技术开发了SQL解析器,包括SQL解析、生成查询计划、优化查询计划、执行查询技术等。但与传统的数据库技术不同,Tajo最终执行查询技术时借鉴了MapReduce的设计思想,它将查询计划转化为一系列任务,这样,执行查询计划实际上就是执行这些任务,而每一个任务就是一个计算单位,同时Map Task和Reduce Task一样。

发表评论