 023-68661681
023-68661681
 返回
返回

产品优势:
高速:运行程序的速度在存储器中比Hadoop MapReduce快上百倍,在磁盘中比Hadoop MapReduce快数十倍。
Spark 拥有一个先进的DAG执行引擎,支持循环数据流和内存计算。
易用:编写Java、Scala、Python、R程序快速高效。
Spark提供超过80个易于构建并行应用程序的高阶运算符,你也可以在Scala、 Python和R shells中对它进行交互使用。
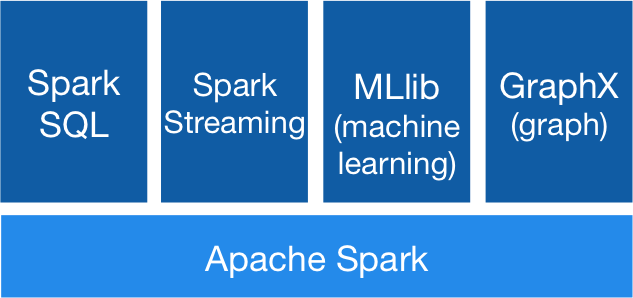
通用:可结合SQL、流媒体和复杂的分析。
Spark支持一系列元件库堆栈,包括SQL与 DataFrames,用于机器学习的MLlib ,GraphX,Spark Streaming。你可以在同一个应用程序无缝地结合这些元件库。

无处不在:Spark可以运行在Hadoop、Mesos、standalone以及云端。它可以访问包括 HDFS、 Cassandra、 HBase和S3在内的不同数据源。
你可以使用其独立集群模式来运行Spark,运行在 EC2、 Hadoop YARN还是Apache Mesos都不是问题。它可以访问HDFS、Cassandra、HBase、Hive、Tachyon等任意的Hadoop数据源。
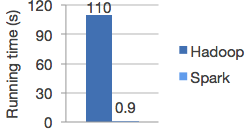
与Hadoop的对比
- Spark的中间数据放到内存中,对于迭代运算效率更高。
- Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
- Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
这些多种多样的数据集操作类型,给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。





发表评论