 023-68661681
023-68661681
 返回
返回

1、HBase定义
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
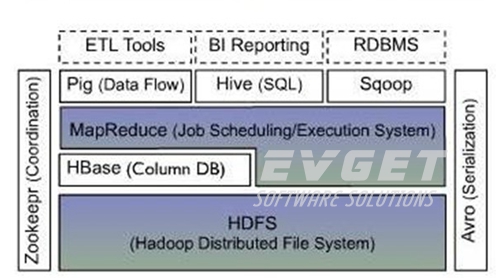
2、HBase特性:
- 高可靠性
- 高效性
- 面向列
- 可伸缩
- 可在廉价PC Server搭建大规模结构化存储集群
3、HBase与RDBMS的对比
HBase适合于非结构化数据存储的数据库。介于Map Entry 和 DB row之间的一种数据存储方式。而RDBMS是一个遵循“Codd的十二条规律”的数据库。主要区别如下:
数据类型: HBase只有简单的字符串类型,它只保存字符串所有的类型都是交给用户自己处理。关系型数据库可以选择类型
数据操作: HBase操作只有很简单的插入、查询等操作,表与表之间是分离的,没有join
存储模式: HBase基于列存储,每个列族由几个文件保存,不同列族的文件是分离的。传统的关系数据库是基于表格结构和行模式保存的
数据维护: HBase更新操作时,旧的版本仍然保留,实际上时插入了新数据。传统关系数据库是替换修改
可伸缩性: HBase能够容易的增加或者减少硬件数量
4、数据模型

组成部件说明:
Row Key:Table主键行键Table中记录按照Row Key排序;
Timestamp:每次对数据操作对应的时间戳,也即数据的version number;
Column Family: 列簇,一个table在水平方向有一个或者多个列簇,列簇可由任意多个Column组成,列簇支持动态扩展,无须预定义数量及类型,二进制存储,用户需自行进行类型转换。
5、系统架构
组成部件说明
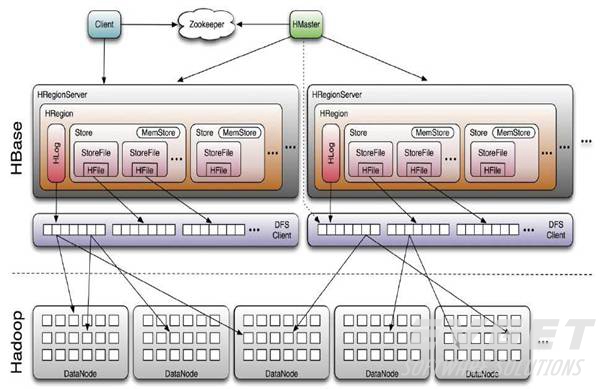
Client:
使用HBase RPC机制与HMaster和HRegionServer进行通信
Client与HMaster进行通信进行管理类操作
Client与HRegionServer进行数据读写类操作
Zookeeper:
Zookeeper Quorum存储-ROOT-表地址、HMaster地址
HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
Zookeeper避免HMaster单点问题
HMaster:
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行
主要负责Table和Region的管理工作:
1 管理用户对表的增删改查操作
2 管理HRegionServer的负载均衡,调整Region分布
3 Region Split后,负责新Region的分布
4 在HRegionServer停机后,负责失效HRegionServer上Region迁移
HRegionServer:
HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据
6、表的设计
在表结构设计时,HBase里有tall narrow和flat wide两种设计模式,前者行多列少,整个表结构高且窄;后者行少列多,表结构平且宽;但是由于HBase只能在行的边界做split,因此如果选择flat wide的结构,那么在特殊行变的超级大(超过file或region的上限)时,那么这种行为会导致compaction,而这样做是要把row读内存的~~因此,强烈推荐使用tall narrow模式设计表结构,这样结构更趋近于keyvalue,性能更好。
本文参考hbase.apache 转载请注明转载自慧都控件网




发表评论