 023-68661681
023-68661681
 返回
返回

IT架构实现云化已经是企业IT战略的大势所趋。无论是采用私有云技术还是公有云技术,都要求软件具备云环境的适应能力。作为企业最重要的数据资产,依赖于底层的数据管理软件进行有效的管理。为实现从海量数据中得到实用的知识和信息,如何高效组织数据的存储和查找的技术一直在演进。从早期的层次型数据库到关系型数据库,从SQL数据库到NoSQL数据库再到处理非结构化数据的Hadoop、图数据库等平台,一直在发展变化,现在可以说是百花齐放,百家争鸣。
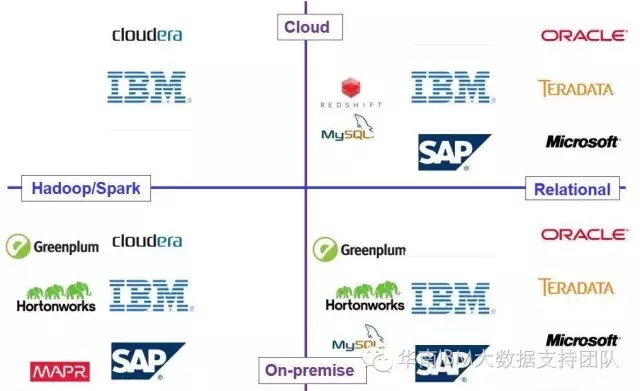
云技术的兴起,连数据存储的位置也有了更多的选择,数据可能存储在用户的数据中心,也有可能存储在某公有云供应商平台中。所以对于用户而言,如何在不同的基础架构、不同的数据库存储平台中、云下云上都保持体验的一致性,应用访问、开发、迁移的平滑性以及数据安全性,保护IT技能的投资,变得异常重要。IBM的下一代数据分析平台,为实现以下的蓝图而重新进行设计和研发。

对于用户而言,信息可视化工具可能使用流行的例如Cognos或Tableau等产品,数据挖掘可能使用SPSS或R等工具,开发语言可能使用的是Python或Scala等流行语言。数据的存储可能在传统的DB2、Oracle或PDA等关系型数据库中,也有可能在新型的Hbase、Hive或NoSQL数据库中。新兴的互联网客户数据可能天然就存储在云数据库中等等。我们是否可以设计一个通用的引擎,它既可以提供一个统一的接口,屏蔽下面的数据存储异构性,又可能使用一个统一的基于SQL的语言来进行应用的访问和开发呢?答案是肯定的!IBM基于开源的Spark技术开发了下一代的通用数据库引擎Common SQL Analytics Engine和查询访问引擎Fluid Query Engine。
作为早期的DB2关系型数据库,为了灵活支持zOS,Unix/Risc架构或WinTel架构,同时为满足客户弹性扩展和支持不同的工作负载,从7版本开始就提出的Universal Database的概念,即一个统一的数据库SQL引擎,就可以支撑不同的体系架构。8、9、10版本后,这个体系架构得到了极大的扩展,通过HADR、DPF、PureScale、BLU、GDPC等功能模块的扩展,在统一的SQL引擎之下,就完美的支撑了用户的不同的工作负载。
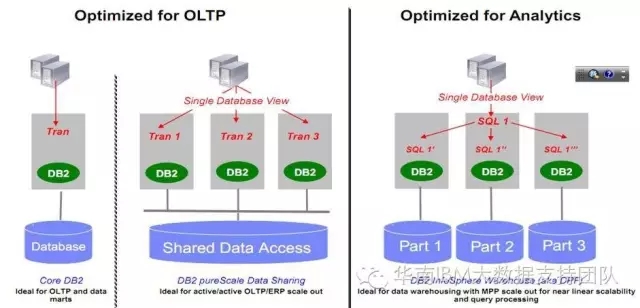
但IT架构在不断地进化,云环境还发展出虚拟化技术、容器技术等为支撑海量访问、多租户访问和快速部署扩展的架构。移动互联网的发展又极大的推动了与用户互动而产生大量的非结构化社交媒体、语音、图像、视频或传感器的数据,因此数据形式有了更多样化的存在。为解决以上的挑战,IBM也通过技术创新或收购等方式,提供了基于开源技术研发的Hadoop产品BigInsights、NoSQL数据库或一体机数据仓库PDA等方案。但是随着客户云化的步伐加快,以上的各种方案之间的架构差别,逐渐成为用户的技术瓶颈。各个方案数据管理的实现不同,导致DBA管理运维、应用开发的难度不断加大。基于移动互联网等云化应用的需求,需要更灵活的体系架构以支撑海量访问、突发用户增长、7*24不间断访问、敏捷开发等的挑战。为此目的,IBM在下一代分析引擎设计中,采用了通用分析引擎的策略,即统一分析引擎,以支撑用户在不同的环境中部署数据应用,不论其将部署在原有数据中心的架构中,亦或私有云甚至是公有云的环境。这种机构将提供给用户极大的灵活性,代码编写一次,可以运行在任何环境中,同时保证DBA的运维体验一致!

首先目标是统一IBM自己的数据存储库代码。新发布的云上关系型数据库引擎dashDB、经典的DB2 11版本、适合私有云部署的dashDB on Local、IBM Hadoop BigInsights和未来即将发布的新一代数据仓库一体机设备PDA,都将构建在统一的分析引擎代码上,用户将可以实现代码仅写一次,随处部署运行。对于DBA而言,不论在哪种库进行操作,操作处理模式统一。对于已经部署在某个平台上的用户而言,未来不论是迁移到云上或构建自身的私有云环境,数据以及应用都将平滑迁移。对于工具的开发商而言,仅认证一个平台,就可以平滑支持其它所有的平台。
因此,不论用户目前还在使用传统的Power架构,采用DB2支撑其核心交易体统,它可以逐步升级到DB2 11版本,享受到未来过渡到云的通用分析引擎能力。若用户即将部署私有云环境,可以采用dashDB on Local的方案,它基于容器进行部署,可以支撑PB级数据的海量扩展,同时具备通用SQL数据库引擎能力,运维体验、开发接口与其使用核心交易DB2保持一致。或直接采用PDA的方案,它一体化软、硬件实现方式,可以更简化运维管理,但管理体验、开发方式也和核心系统的数据库保持一致。用户若直接基于公有云的服务,开发各种应用,其上的dashDB云数据服务,和云下的数据库管理、开发体验也是保持一致。最后即使用户选择使用Hadoop来存储其非结构化数据,内置的BigSQL引擎,其运维管理、开发接口也和其在使用的核心交易数据库保持一致的体验!看到现在,你是否觉得很Cool!不论是交易负载亦或分析负载,不论是云下使用还是云上开发运维,所有的技能、软件资产都得到了保护,你的云化大计有了充分的保障!
对于数据已经存放到了不同的数据库中,制定数据统一存放的策略并不现实。因此数据离散化存放,多库存储将是最可能的现实。对用户而言,如何进行统一访问接口,透明访问所有的数据源,或在不同数据源中迁移数据,将成为一个关键的挑战。IBM提供数据访问的通用引擎Fluid Query Engine,它充分考虑客户的数据虚拟化的现实,统一接口,解决客户难题。
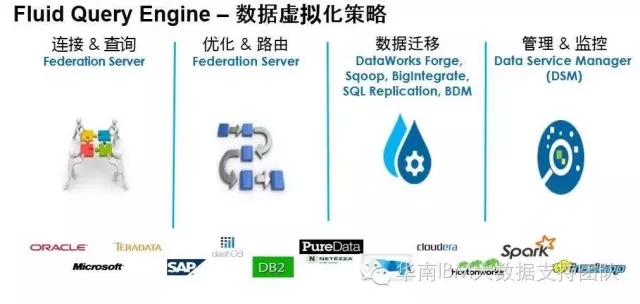
由此,通过Common Analytics Engine以及Fluid Query Engine,统一基础架构的实现代码,简化应用访问不同数据的接口,从而实现用户的云下云上数据访问体验一致,保护已有开发IT资产,助力用户早日实现云化大计!
快来体验吧,下载试用IBM Analytics Platform产品!
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381



发表评论