 023-68661681
023-68661681
 返回
返回

在IBM SPSS Modeler中,每个算法都会有相应的默认参数设置,对初学者来说,即使不是很懂算法,也可以生成模型结果,但在实际项目中,我们为了使得模型更加的优化,提升模型的准确率,经常会对算法的参数做一些相应的调整,那么今天,我们给大家介绍两个参数,分别是Bagging和Boosting,让大家了解下它们是怎么用的,能带来什么样的模型优化结果。
用途:
Bagging和Boosting都是用来提高模型准确率的方法。
计算逻辑:
Bagging是Bootstrap Aggregating的一种方式,是一种根据均匀概率分布从数据集中重复抽样(有放回的)的技术。每个自助样本集都和原数据集一样大。由于抽样过程是有放回的,因此一些样本可能在同个训练数据集中出现多次,而其它一些却可能被忽略。假设我设置了Bagging的次数是10,也就是说我会根据上面的重复抽样方式,抽取10份数据,分别构建10个模型,得到10个预测结果,对最后的判定,如果是分类问题采用投票方式,对回归问题采用简单平均方法。
Boosting主要是AdaBoost (Adaptive Boosting),初始化时对每一个训练集赋相等的权重1/n,然后用该学算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在后续的学习中集中对比较难的训练例进行学习,从而得到一个预测函数序列h_1,⋯, h_m , 其中h_i也有一定的权重,预测效果好的预测函数权重较大,反之较小。最终的预测函数H对分类问题采用有权重的投票方式,对回归问题采用加权平均的方法对新示例进行判别。
Bagging与Boosting的区别:
二者的主要区别是取样方式不同。Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging。Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boosting的各轮训练集的选择与前面各轮的学习结果有关;Bagging的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于像神经网络这样极为耗时的学习方法,Bagging可通过并行训练节省大量时间开销。
Bagging和Boosting都可以有效地提高分类的准确性。在大多数数据中,Boosting的准确性比Bagging高;在有些数据集中,Boosting会引起退化------过度拟合。
IBM SPSS Modeler中的应用:
在IBM SPSS Modeler中,可以设置Bagging或Boosting功能的在算法包括:
Neural
Network
CHAID
QUEST
C&RT
Linear
以CHAID决策树为例:
接下来我们通过电信流失客户分析模型的创建来体验下这两个参数的设置对预测结果的影响。
首先,我们创建一数据流文件 ,如下图:
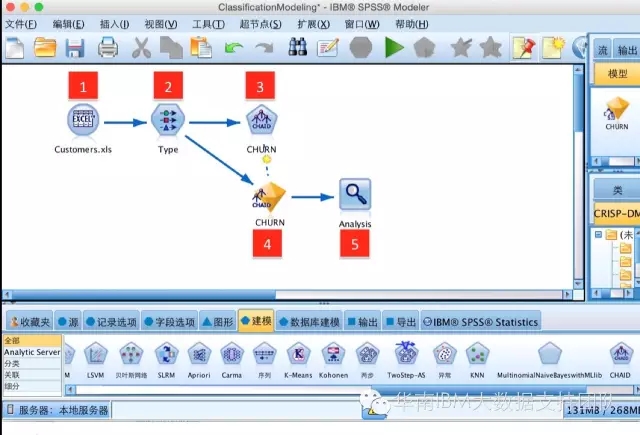
Step1:连接数据源Excel文件,文件内容如下:
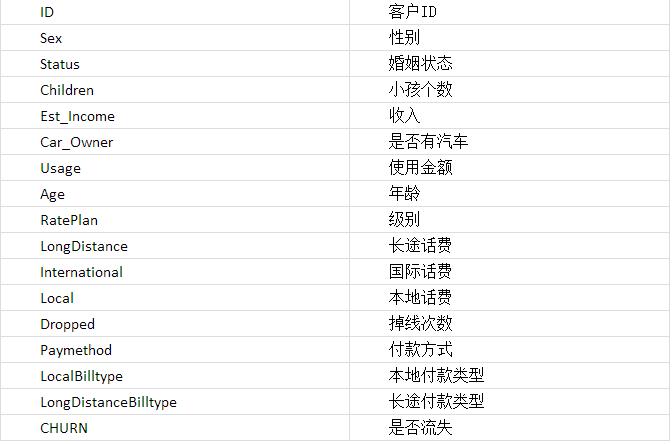
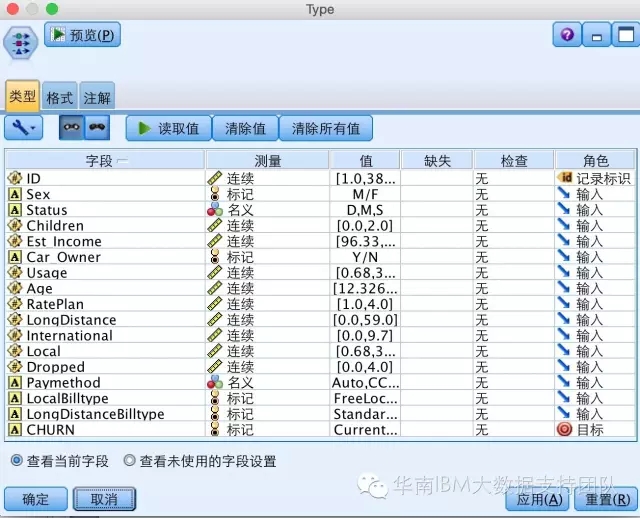
Step2:类型节点设置影响因素及目标:
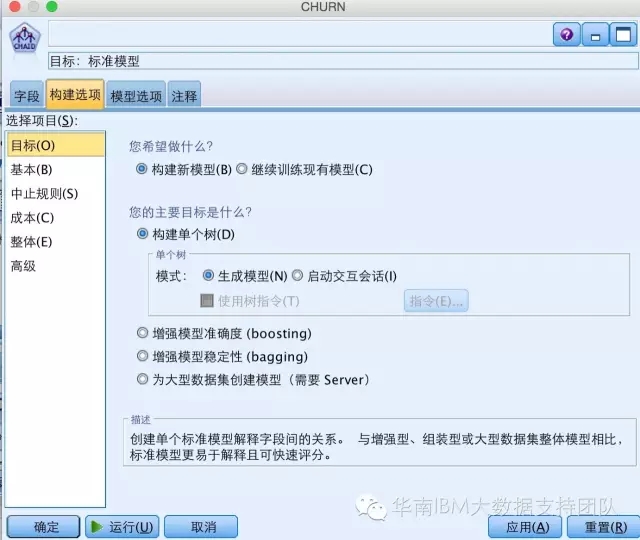
Step3:选择CHAID决策树算法,并使用默认参数设置生成模型:
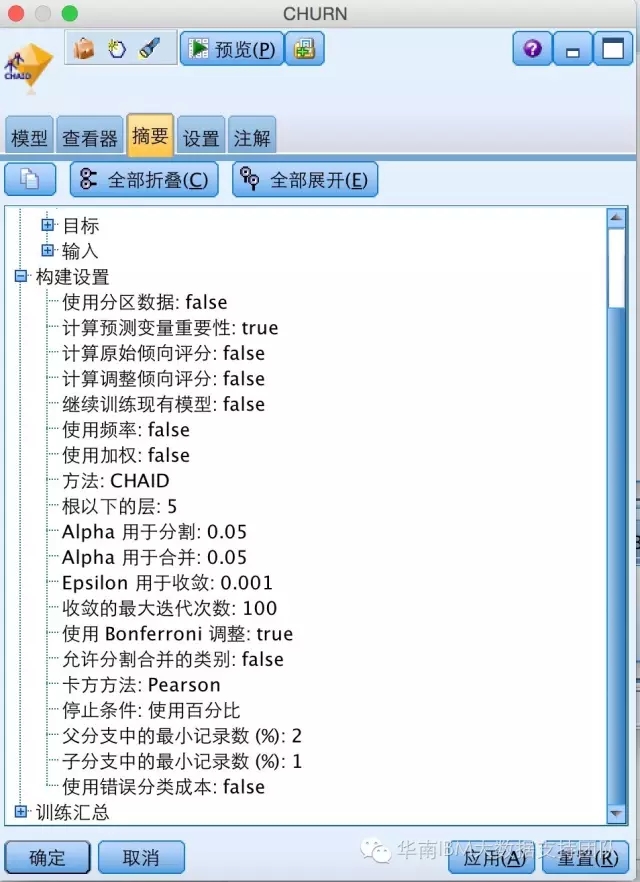
Step4:生成的模型结果,可以在摘要面板查看默认的参数设置内容:
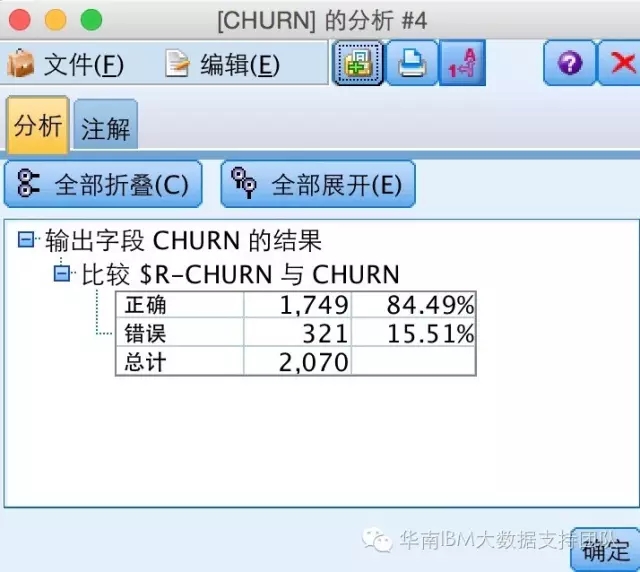
Step5:通过评估节点查看模型准确率为84.49%:
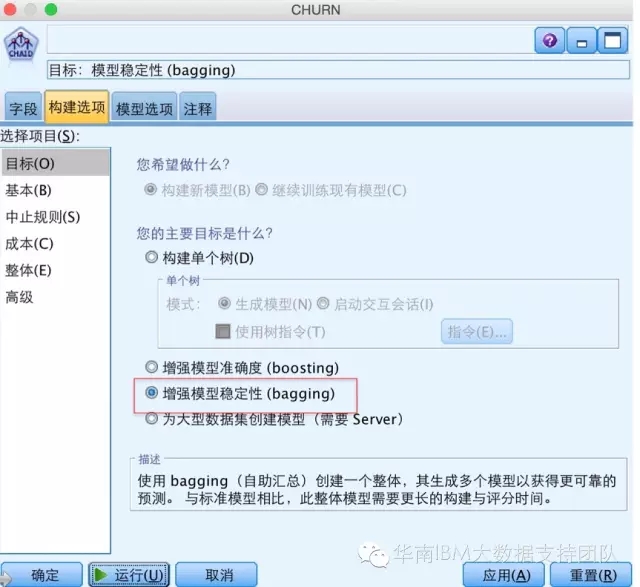
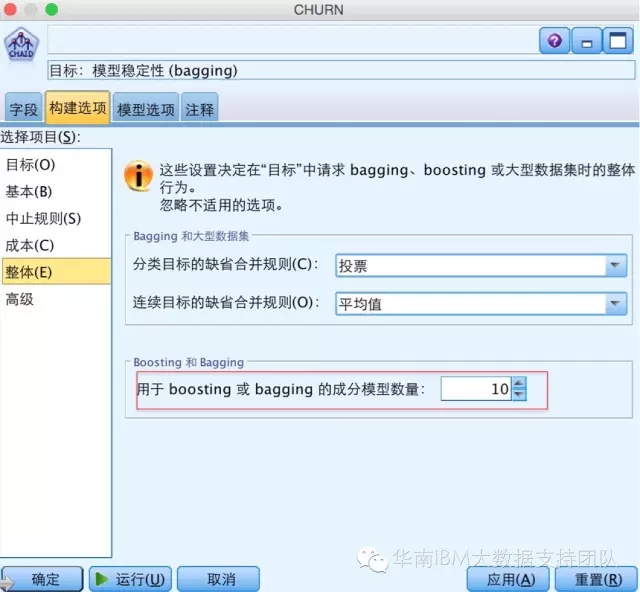
接下来,我们第一次更改算法的设置内容,在构建选项的目标面板中,选中“增强模型稳定性”,在整体面板中,设置模型数量为“10”。
重新运行模型后,可以看到,得到10个模型结果及各自的准确率:
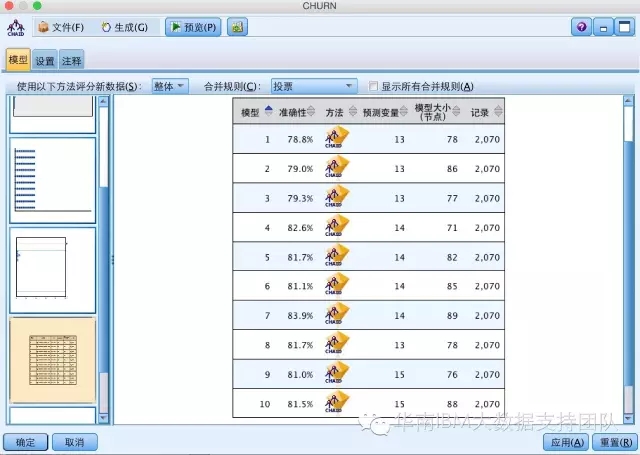
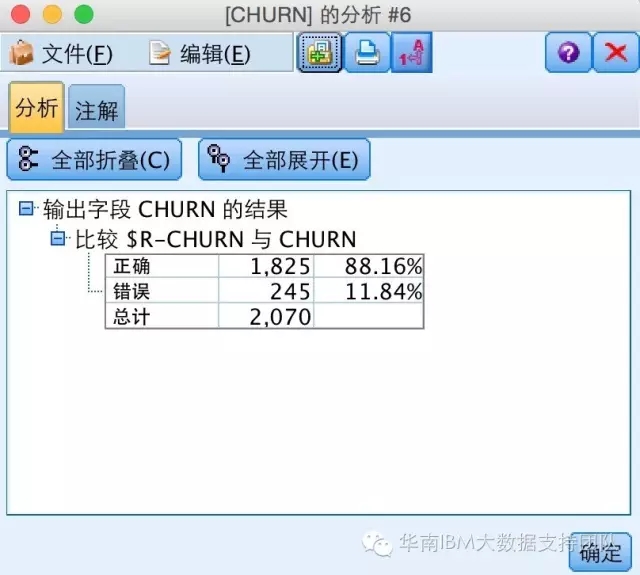
再用评估节点,看到新模型准确率与之前的准确率相比,增加到88.16%:
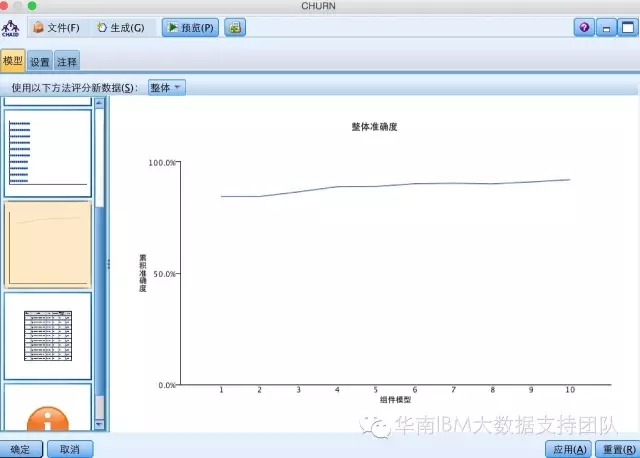
同样的道理,如果我们设置为Boosting选项,生成的模型可以看到它的准确度缓慢提升:
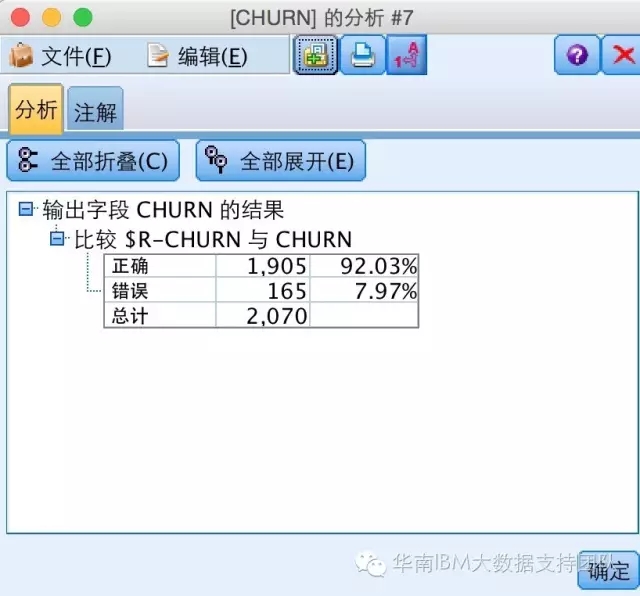
同样的,用评估节点,可以看到模型的准确率会增加到92.03%:
总结:
通过上面的例子,我们可以看到使用Bagging和Boosting对模型带来的影响,可以在实际项目中尝试着使用,当然啦,因为使用这两个选项后,它的计算量会大大增加,比如原来要构建一个决策树模型,现在要构建N个(取决于你设置的模型个数),因此计算量是原来的N倍,所以,请耐心等待……
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
详情请咨询在线客服!
客服热线:023-66090381




发表评论